
I added an eval framework to an existing AI pipeline over a weekend. The cheapest model was barely better than random, and confidence scores weren't telling anyone anything useful. Here's what I found, and why engineering leaders should own this rather than leaving it to the data science team.
One of my devops engineers once cut our AWS costs by six figures without changing a line of application code. He accomplished this by reviewing our S3 data retention practices and moving data to cold storage sooner. The optimization was available the whole time, but no one had stopped to ask whether the storage tier matched the actual business need.
LLM usage deserves the same review. Most engineering leaders I work with have started thinking seriously about AI, but the conversation is almost entirely about developer experience: using coding assistants, reviewing AI-generated code, and generating documentation. I'm not yet hearing the operational questions being asked as often: are we using the right model for the job, and how are we balancing cost and quality. Leaders own budget and operational excellence, but when it comes to AI pipelines, few have developed the same discipline they'd apply to any other infrastructure decision.
That gap is what I wanted to test. The pattern: build a lightweight eval framework on top of an existing LLM pipeline, measure quality across model tiers, and see whether the cost-quality tradeoffs are actually what they appear to be. I already had a good test case, and set off to see what I could build in a weekend.
pr-impact-analyzer is a pipeline I built to automatically assess the risk of incoming pull requests. The input is the diff, PR description, and multiple heuristic metadata fields gathered deterministically. The LLM analyzes this structured data and returns a risk level (low, medium, or high), a recommended action, a confidence score, and its reasoning. I'd been running the pipeline on kubernetes/kubernetes PRs as a test dataset. Everything appeared to be working, but as I began to explore operationalizing this agent at scale, I needed to answer the question of which model to use in production.
Model pricing spans orders of magnitude, from open-source (Llama) to a few cents per call (Claude Opus). For a pipeline processing thousands of PRs a month, that unit cost difference compounds quickly. Every engineering leader I know has had this conversation: "Do we really need the expensive model? The cheaper one looks good enough."
The problem is most orgs have not defined what "good enough" means, not only in technical terms but also in terms of outcome and business context. When I ran the same PR through different models, I'd sometimes get meaningfully different risk assessments, all returned with similar confidence scores. I wasn't expecting complete agreement across models, but when they disagreed, I had no rigorous way to know which verdict was closer to correct. In a tool whose job is to reduce the number of production incidents, this matters. If I was going to recommend a model for a pipeline that routes pull requests through different review tracks (where a wrong label means either unnecessary friction for developers or an under-reviewed risky merge), I needed to separate noise from signal.
So I spent a weekend adding an eval framework. Here's what it found.
This Is Not a Data Science Project
Building a model evaluation like this is not an ML initiative that requires a data science team. What you do need is a test set, a gold standard, and infrastructure that lets you evaluate models consistently. For an existing pipeline, most of that infrastructure is already there.
I came to this problem with a background that goes back to building and validating production classifiers in the early 2000s, well before "LLM" was in anyone's vocabulary. I have experience with hand-engineered features, precision/recall tradeoffs, and the full classical ML evaluation playbook. The methodology I used here is the same discipline I applied then, but it isn't exclusive to data science or academia. It starts with the questions that any engineering leader who has shipped production software already knows how to ask: What are the failure modes? How do we measure them? What does the cost of a wrong answer actually look like?
Most teams pick an LLM based on hype (latest, greatest), familiarity, or general benchmarks. They ship the feature and move on, watching error rates and maybe latency. What they're missing is a baseline: something to compare against when the model gets updated, when the prompt changes, when data drifts in production, or when someone raises the cost question again six months later. The eval framework is that baseline.
How I Set It Up
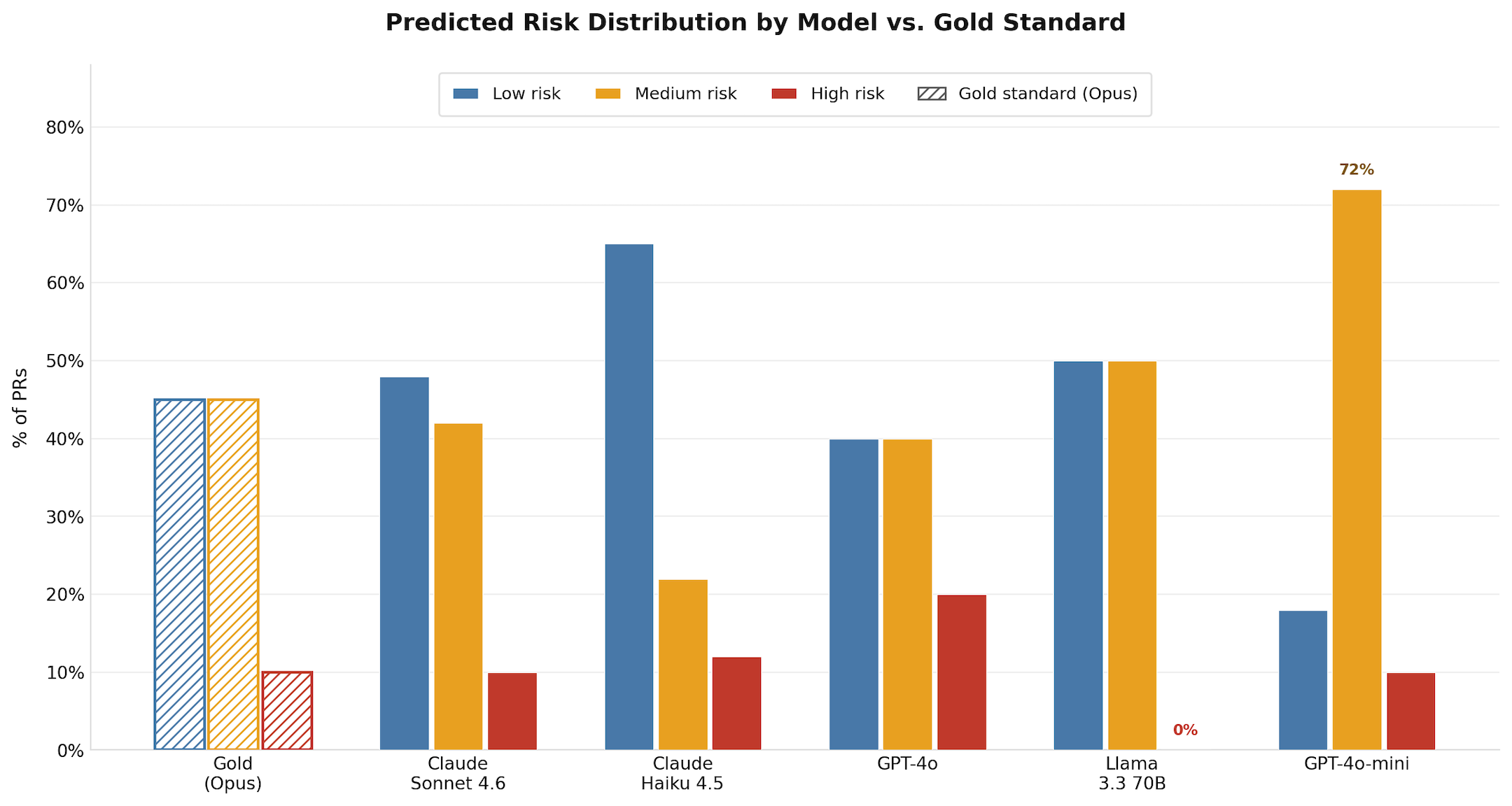
The test set was 40 pull requests from kubernetes/kubernetes, with enough variety in change type and risk profile to make the classification non-trivial. The distribution skewed toward lower risk: roughly 4 high, 15 medium, 21 low. That reflects reality in an actively maintained repo where most PRs are refactoring and cleanup, but it matters for reading the accuracy numbers. A naive classifier that predicted "low" on everything would score about 50% on this dataset. Keep that in mind when you see GPT-4o-mini's results.
The gold standard was Claude Opus, prompted with step-by-step reasoning before producing its verdict. I deliberately asked it to reason through system implications before labeling. Opus isn't ground truth in an absolute sense; it's the best available proxy for what a careful expert reviewer would produce. Every other model's results are measured against it. This pattern has a name: LLM-as-judge. It's a practical choice when labeled data doesn't exist and you need to move quickly. The stronger alternative, if you can get it, is human classification by someone who actually knows your codebase: a senior engineer who understands your deployment context will produce a more domain-accurate gold standard than any general-purpose model. For getting started, Opus is a reasonable proxy. For a production eval you plan to maintain long-term, it's worth investing in even a small set of human-labeled examples.
The metrics I cared about weren't just accuracy. Because the cost of errors is asymmetric (missing a high-risk PR costs you an incident, while over-flagging a safe one costs a developer review time and erodes trust), I tracked four things:
- Risk accuracy (exact match with Opus)
- Risk accuracy within one tier (near-miss vs. severe miss)
- Recommendation accuracy (did the model's advised action align with Opus?)
- Confidence calibration (does the model's stated confidence actually correlate with whether it's right?)
That last one turned out to be the most important metric I wasn't planning to care about.
The infrastructure was LiteLLM for model-agnostic API calls and Langfuse for tracing, prompt versioning, and eval score logging. Every call is tagged with model ID, PR ID, and eval run ID. The point of this setup isn't sophistication: it's rerunability. When a model gets updated or I change the prompt, re-running is trivial. That's what makes it a monitoring tool rather than a one-time benchmark.
The models:
| Model | Cost / PR | Source |
|---|---|---|
| Llama 3.3 70B | $0.00 | GitHub Models (free) |
| GPT-4o-mini | ~$0.0006 | GitHub Models (free tier) |
| Claude Haiku 4.5 | ~$0.0075 | Anthropic |
| GPT-4o | ~$0.011 | GitHub Models (free tier) |
| Claude Sonnet 4.6 | ~$0.022 | Anthropic |
| Claude Opus (judge only) | ~$0.15 | Anthropic |
Opus is the reference point only. It scores 100% by definition and isn't a production candidate, but keeping it in the table makes the price spectrum visible.

One caveat on precision: 40 PRs is enough to surface behavioral failure modes, schema reliability issues, and calibration problems, which is exactly what happened here. It's not enough to make statistically precise claims about small accuracy differences between models. A 3–5 point gap could flip with a different sample. The directional findings are solid; treat the specific numbers accordingly.
What I Found
The cheap model looked fine. It wasn't.
GPT-4o-mini achieved 57.5% risk accuracy. Random guessing on a three-tier problem gets you about 33%. The naive "always predict low" classifier gets you about 50% on this particular dataset distribution. GPT-4o-mini's effective lift over a naive classifier is marginal.
What surprised me most is that if I hadn't defined a gold standard baseline, this model's low accuracy would have been invisible because the output "looks fine". The reasoning field produces coherent text. The model returns a valid schema every time. The assessments read as plausible. This is exactly the failure mode that "looks fine" conceals: you'd have to run the eval to see it.
Kubernetes PR #137946 is the example that makes it concrete. The diff is minimal: 3 additions, 5 deletions across 4 files, flipping a single kubelet feature gate default from false to true to re-enable PLEGOnDemandRelist in version 1.36. GPT-4o-mini returned: medium risk, monitor, 75% confidence. A sensible read of the diff size and stated rationale. What it missed: PLEG (the Pod Lifecycle Event Generator) is the kubelet subsystem that drives pod state reconciliation on every node. A regression here doesn't affect one pod; it manifests as state drift across the entire cluster. Add the PR's prior flake history (the feature had been disabled after exposing a test flake) and the absence of recorded approvals, and Opus returned high risk. GPT-4o-mini returned medium. Both assessments sounded reasonable. Only one was right.
The operational consequence is direct: deploying GPT-4o-mini for automated PR routing would produce incorrect labels on more than 40% of all PRs. That's not a cost optimization. That's a reliability regression dressed up as one.
Llama had the right accuracy and the wrong operational profile.
Llama 3.3 70B achieved 68.4% accuracy at zero API cost. That puts it below Haiku (75%) and meaningfully behind Sonnet (80%), though still ahead of GPT-4o-mini (57.5%) and GPT-4o (62.5%). If cost were the only metric, Llama would still be compelling. It isn't.
The accuracy number conceals a distribution problem: Llama never predicted high risk on a single PR. The gold standard labeled 4 PRs as high risk; Llama labeled every one of them medium or lower, for 0% recall on the category this pipeline exists to catch. A 68.4% accuracy built entirely on getting low and medium right is not a 68.4% you can operationalize for risk-based routing.
Llama also produced 2 complete JSON parse failures, schema errors on 18.4% of valid responses, and critical failures: high-confidence wrong answers on PRs the gold standard rated high-risk. GPT-4o also produced critical failures despite costing 18x more per PR than Haiku, and had a 12.5% schema error rate. The assumption is that paying more buys reliability. In this evaluation, it didn't. These failure modes don't show up in capability benchmarks. They show up when you test in your actual deployment context.
My honest take: Llama makes economic sense at high PR volumes, where API costs become a real budget line. At $0.022 per PR, Sonnet costs about $22 per 1,000 PRs, roughly one developer-hour. The schema validation, parse error handling, and fallback logic required to run Llama reliably in production will take considerably more than one hour to build and maintain. For most teams at current pricing, Sonnet is the right answer. The case for Llama hardening becomes compelling above roughly 100,000 PRs per month. Below that, the engineering investment doesn't pay for itself.
There's one path that could move Llama's accuracy higher: fine-tuning on your own PR data. A task-specific fine-tuned model can outperform a much larger general one on a narrow classification task. But fine-tuning requires self-hosting, and self-hosting has a real cost floor: cloud GPU instances for a 70B model run roughly $2,000+/month reserved, before staffing. The economics only work above a certain scale. For most teams, this is a later optimization, not a starting point.
Confidence scores are not what you think they are.
This is the finding I didn't expect, and the one with the broadest implications for this pipeline and for any LLM pipeline that uses a confidence score to make routing decisions.
All five models reported average confidence scores between 0.80 and 0.86. Risk accuracy ranged from 57.5% to 80%. The confidence scores don't reflect that variance at all. A model that's wrong nearly half the time is reporting similar confidence to a model that's right 80% of the time.
That alone is a calibration problem. Haiku's result is worse still.
Haiku's average confidence when wrong (86.2%) is higher than its average confidence when correct (82.9%). The model is more assertive about its incorrect assessments than its correct ones. Back to PR #137946: Haiku returned low risk at 87% confidence. Its reasoning: "This is a low-risk feature gate enablement with minimal code footprint. The PR correctly addresses the prerequisite: test flakes exposed by the feature were root-caused and fixed in the referenced PR #137749 before re-enabling." The reasoning is coherent. The confidence is high. What it doesn't do is consider blast radius: that PLEG drives pod state reconciliation on every node, that prior flake history is a caution flag rather than a clearance, that the absence of review approvals in a kubelet behavioral change is a process signal worth weighting. Haiku evaluated the diff. It did not evaluate the system the diff was changing.
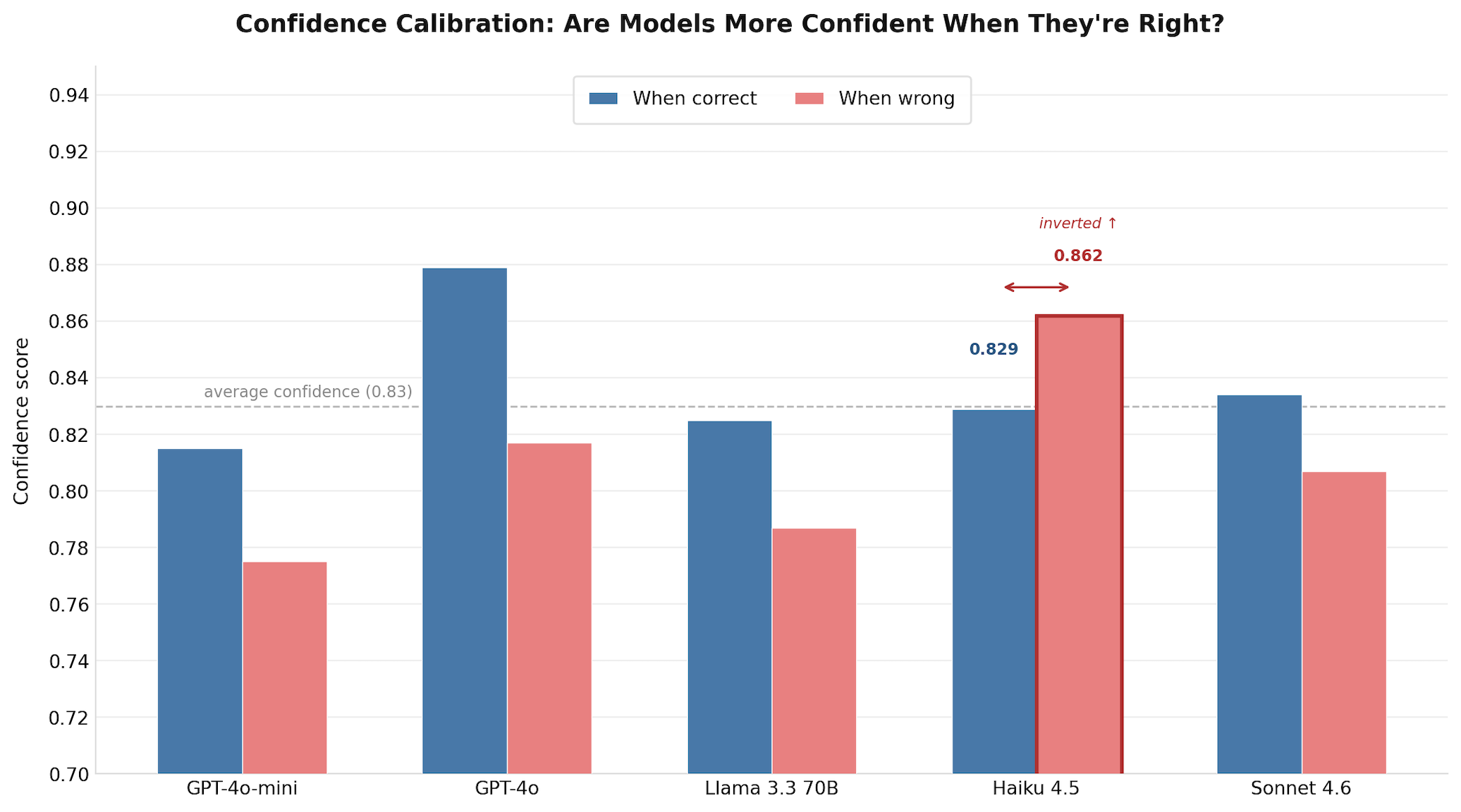
The production consequence of this specific pattern: if you set an auto-approve threshold at confidence ≥ 0.85, you'd be automatically approving a disproportionate share of Haiku's errors. The pipeline looks like it's routing uncertain cases to human review. It's actually waving through the most confidently wrong ones.
This is fixable with prompt tuning, post-hoc calibration, or empirical threshold adjustment, but only if you know the problem exists. You cannot know it exists without running the calibration test.
What to Do With This
Model recommendation, directly:
| Model | Risk accuracy | Cost / PR | Verdict |
|---|---|---|---|
| Claude Sonnet 4.6 | 80% | $0.022 | Use this for automated risk routing |
| Claude Haiku 4.5 | 75% | $0.0075 | Viable for triage, skews toward low labels; fix calibration first |
| Llama 3.3 70B | 68.4% | $0.00 | High volume only; 0% high-risk recall, schema handling required |
| GPT-4o | 62.5% | $0.011 | Schema errors + critical failures, worse value than Haiku |
| GPT-4o-mini | 57.5% | $0.0006 | Not for this task |
For automated PR routing in CI/CD where a wrong label has operational consequences: Sonnet. It's the only model here with zero schema errors, zero critical failures, and calibrated confidence. At $22 per thousand PRs, this is not a meaningful cost. The cost of a single incident from a missed high-risk merge almost certainly exceeds $22.
Don't use overall accuracy as your go/no-go threshold. For any task where failures are asymmetric, the number you actually need is recall on high-risk cases: what percentage of the PRs your gold standard rates high-risk does the candidate model also flag? Llama's 68.4% accuracy, for example, reflects 0% recall on high-risk PRs: every one of the PRs Opus rated high got labeled medium or lower. The accuracy number alone would never tell you that. You need to see the failure distribution, not just the headline.
Run the confidence calibration test. If your pipeline uses a confidence score to route cases to human review, this is the most operationally important thing you can measure. An uncalibrated model doesn't just produce wrong answers; it produces wrong answers it's confident about, which means your human review safety net isn't catching what you think it's catching.
Don't auto-approve. The calibration data in this article makes the case technically: a model that's more confident when wrong than when right is not a safe gating mechanism. But the broader principle holds regardless of which model you use: PR review is a meaningful guardrail, and AI is best used to sharpen human judgment on where to focus attention, not to replace that judgment entirely. Flag, prioritize, and route. Let a person make the final call.
Who should own this? In most orgs, LLM pipelines get built by product teams, platform teams, or whoever has the AI initiative - and once the feature ships, the eval work falls through the cracks. A reasonable default: whoever ships an LLM feature that affects routing, blocking, or user-facing behavior owns an eval baseline at launch. That's not a full MLOps practice - it's a frozen test set, a judge model, and a rerun script. Platform teams can supply the infrastructure; the team shipping the feature needs to define the metrics for their specific task. A staff or principal engineer is the right person to own the pattern itself - not just run it once, but turn it into a repeatable practice that gets applied at every AI product review. If you have that person on your team, this is a high-leverage thing to put in their hands.
From One-Time Benchmark to Durable Framework
The eval framework I built here is rerunnable by design. The test set is frozen. Every call is traced with model and prompt version. Re-running after a model update is one command. That's the difference between a one-time benchmark and an operational monitoring practice, and it's the same discipline that characterized rigorous ML engineering before the LLM era. We used to do this automatically. Somewhere in the transition to prompt-based pipelines, a lot of teams stopped.
The pattern is also portable. If you're running any LLM feature where the output affects routing, prioritization, or automation - risk assessment, ticket classification, support triage - you can build this same baseline. Pick a capable model as judge, define the metrics that match your failure modes, run it on a representative sample, and log everything so you can re-run it. The weekend investment pays for itself the first time someone raises the model cost question and you have an actual answer.
For some of those tasks, the eval will tell you the smaller model is the right call. RAG-based synthesis is a case a lot of teams get wrong: when the relevant information has already been retrieved and placed in context, the generation step is closer to comprehension than open-ended reasoning. The model doesn't need broad world knowledge or deep inference about system implications - it needs to read and summarize. A cheap model often handles that just fine, as long as your chunking and embedding strategy is solid. The point isn't to always use the expensive model. It's to measure before you decide.
The code for this project, including the evaluation pipeline, is available at github.com/lilacmohr/pr-impact-analyzer.
Making It a Practice
The goal here isn't for your team to clone my repo. It's to build the habit of measuring before deciding, and to make that habit visible across your organization.
Here's a concrete starting point. Find one LLM pipeline your team is already running in production - something that produces a classification, a recommendation, or a routing decision. Pick a principal or staff engineer who knows that domain well. Together, select 30-50 representative examples and have them label the expected correct output. That's your gold standard. Then run your existing model against it, pick one cheaper alternative, and compare. You don't need LiteLLM and Langfuse to start - a spreadsheet and two API calls is enough to surface whether a gap exists.
Once you have results, host a lunch-and-learn. Walk the team through what you measured, what the models got wrong, and what the calibration data showed. The conversation that follows - about what "good enough" actually means for your specific use case, and whether the team even agrees on that - is often more valuable than the numbers themselves. It surfaces assumptions that were never made explicit.
From there, the question of which model to use becomes an engineering decision with evidence behind it, not a gut call dressed up as a cost conversation.