
Part three of a three-part series. Part one: Cognitive Drain: The Silent Risk of AI-Assisted Development. Part two: What Just Happened? Capturing Engineering Decisions in the Age of AI.
When a principal engineer on my team (let's call him Bill) announced he was leaving, I understood immediately what we were about to lose. Not the code - we had the code. Not the documentation - we had some of that too. What we were losing was the reasoning behind the decisions: why the service boundary was drawn where it was, which integration assumptions had quietly become load-bearing, what had been tried before the current architecture and failed. We scheduled (and recorded) brain-dump sessions, but knew that the day would come when we would run into a system issue or a new architecture proposal and would collectively say "if only Bill were here..."
Two years later, a new engineer asked why a particular architectural constraint existed in the first place, and nobody could answer. The recordings were in a shared drive somewhere, describing a system that had continued evolving without them. The knowledge transfer worked, but the knowledge just had nowhere to land that kept it alive.
In Part one of this series, we named the risk of cognitive drain. In Part two, we covered what to coach your team to do about it: measuring for early warning signals, a framework for what deserves a formal record, and the narration workflow - the practice of articulating decisions at the moment they're made, so the reasoning doesn't evaporate with the session - to introduce in a 1:1 this week. Those practices create artifacts. This article is about building the infrastructure that keeps them alive: where records live, who maintains them without the practice collapsing under its own weight, and what the governance model looks like when AI agents stop assisting with decisions and start making them autonomously.
Redefining What Staff+ Engineers Own
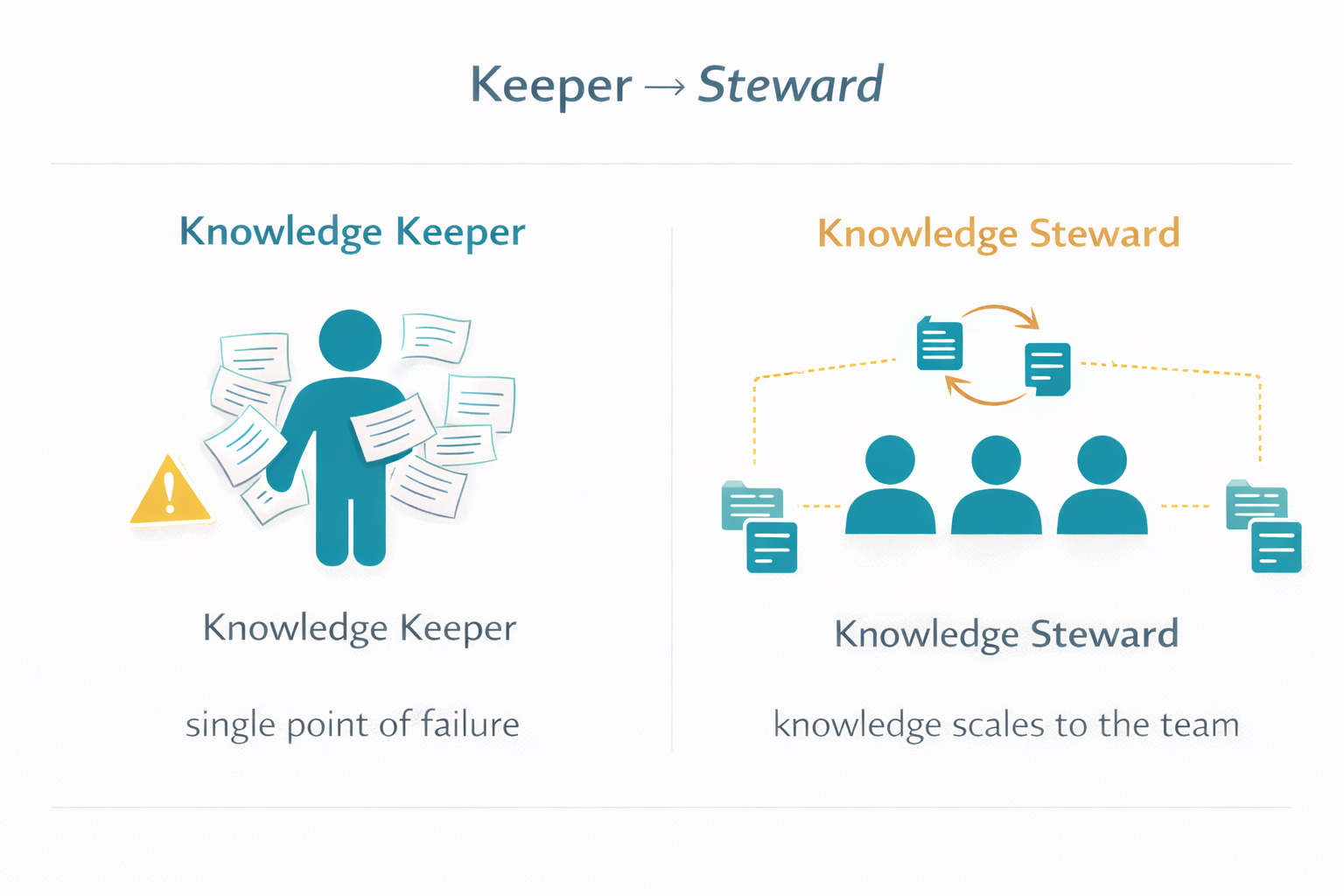
Most Staff+ frameworks like Larson's Staff Engineer and Reilly's The Staff Engineer's Path describe the role in terms of scope and influence, not in terms of system knowledge. The reality on most teams, though, is that Staff+ engineers become the de facto keepers of system knowledge because they've been there the longest and no one ever built a better knowledge-sharing system. Bill was exactly that kind of keeper - and his departure made clear what happens when the knowledge-sharing system is a person.
The model of having the majority of knowledge in the brains of a few individuals, whether intentional or not, has risks. In the age of AI, the model of Staff+ as keepers of knowledge doesn't protect against gradual, distributed cognitive drain because no single person can compensate for understanding that isn't forming across the whole team.
The shift is from keeper to steward. A Staff+ engineer operating as a knowledge steward doesn't need every system detail memorized - they need to ensure that the reasoning behind significant decisions is captured in a form their teammates can use, and that they can evaluate whether a proposed change is consistent with past decisions rather than simply checking whether it passes tests. This is the multiplier model of Staff+ impact made concrete: your knowledge scales to the team rather than remaining locked in one person's memory, and it persists past your tenure rather than draining with it.
Here's the coaching language for a 1:1:
"I'm not asking you to have every system detail in your head. I'm asking you to make sure the reasoning behind our significant decisions is captured in a form your teammates can query. I want to make sure that when someone proposes a change that touches your service's contracts, you can evaluate it against why we made those decisions, not just whether the tests pass. Your job is to ensure the team doesn't have to depend on you being in the room."
The goal of knowledge stewardship isn't just organizational resilience. It's freeing your most senior engineers from being the single point of failure for their own domain so they can work on harder problems (and get occasional vacations).
Where the Artifacts Live and How They Stay Alive
This is where most knowledge management efforts die quietly. The artifacts get created, land in Confluence or a shared drive, and are never touched again - not because engineers are negligent, but because the tooling creates too much friction between the moment of need and the moment of retrieval.

The Confluence graveyard isn't a discipline problem; it's an architecture problem. The solution is to make the artifacts live where engineers already work, and to automate the overhead of keeping them current.
In Planview's 2018 survey of 650 project professionals, respondents reported losing up to 20 hours per month because collaboration tools were not integrated or centralized across the organization (source). That friction compounds when what's fragmented isn't just tasks and tickets, but institutional reasoning - the decisions that explain why your system is shaped the way it is.
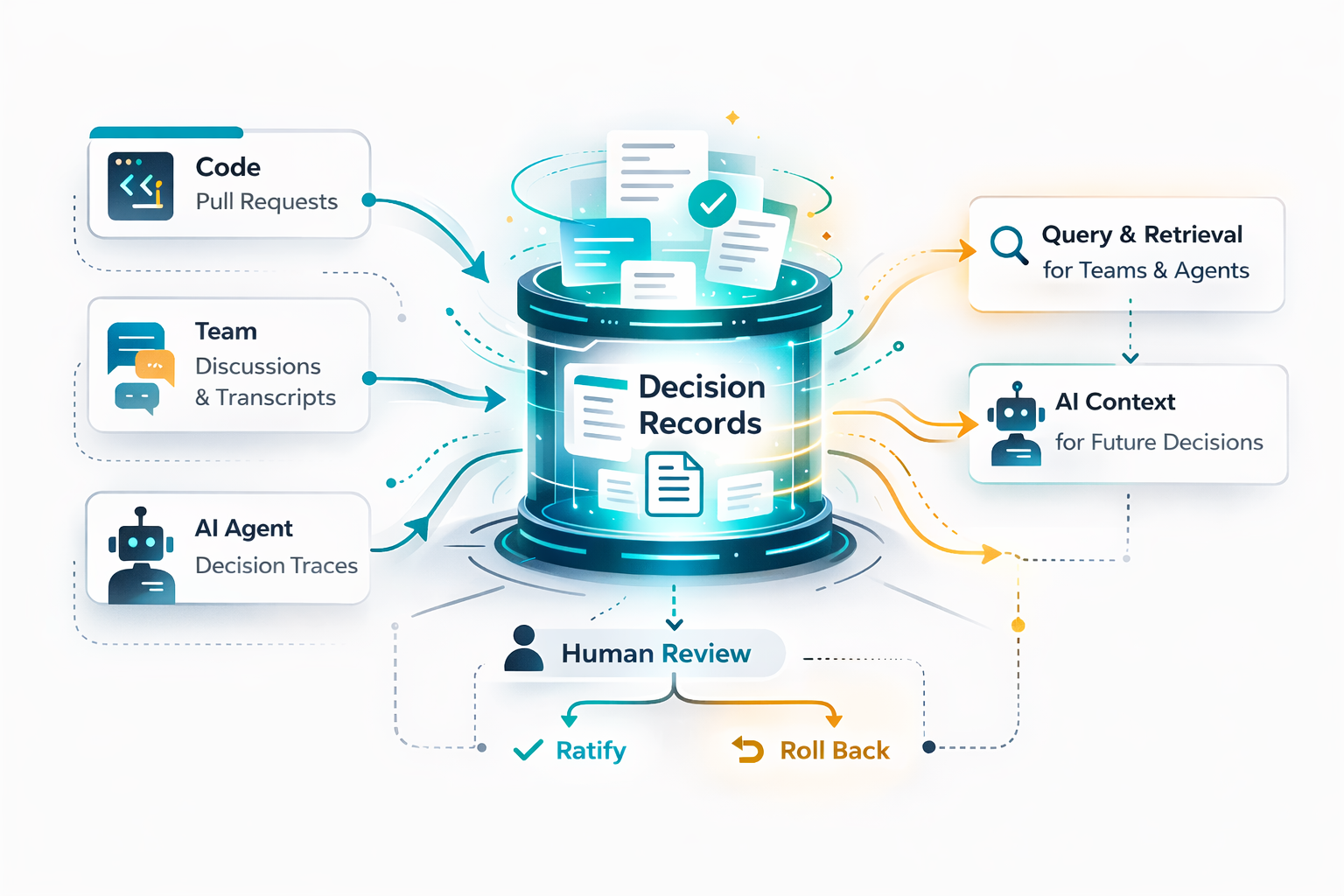
Before getting into the mechanics, I want to address the assumption that makes most teams complacent about this: "We can just ask the AI what was decided." AI is great at explaining what a piece of code does, but it can only guess at why a decision was made if that 'why' isn't captured anywhere. Agent sessions are stateless, with no persistent memory accumulating across your team's interactions with coding tools unless you've explicitly built infrastructure for it. Your engineers' chat histories are not a knowledge base. They're not searchable, not versioned, not connected to the codebase, and in many cases not retained at all beyond a rolling window. The artifacts described below aren't supplementary to AI memory - they are the memory. Without them, the reasoning behind your system's current shape exists nowhere.
The artifact home: your repository, not a wiki.
Decision Records live in the codebase alongside the code they describe - typically in a /decisions or /adr directory at the service or repository level. This matters for three reasons:
- Records version with the code. You can trace the evolution of a decision alongside the evolution of the implementation.
- Engineers encounter them in the tools they're already using - their IDE, code review, GitHub search - rather than context-switching to a separate system.
- They participate in pull request workflows naturally. A PR that changes a service contract can be required to include or update a Decision Record as part of the review checklist.
The records themselves are Markdown, lightweight enough that there's no tooling dependency and readable directly in any code review interface.
Automated update suggestions, not manual maintenance.
Manual documentation maintenance fails because it competes with shipping. The sustainable pattern is to automate the suggestion of updates while keeping humans in the approval loop.
Here's the workflow in practice:
- A knowledge-sharing session happens - a sprint demo, a lunch and learn, an architecture review, or a team retrospective.
- The recording or transcript is processed by AI to identify new decision content worth capturing, and existing Decision Records that should be updated or superseded.
- The AI generates draft updates and opens them as pull requests against the repository.
- Staff+ engineers review and merge them as part of their regular workflow, the same way they'd review any other PR.
This is the pattern I would have applied retroactively to those knowledge transfer sessions after Bill's departure. The raw material was all there, comprising hours of conversation, context, and reasoning. What was missing was the automated bridge between those recordings and a versioned, queryable knowledge base - and the workflow that would keep that base current as the system continued to evolve.
A PR intelligence pipeline - one that uses AI to summarize pull requests and qualify their impact and risk - is a natural complement, and one I've built and deployed on my teams: it flags when a merged change touches a component with documented contracts and surfaces the relevant Decision Records automatically during review. The measurement and the knowledge base reinforce each other: the pipeline identifies what changed and at what risk level, and the records explain why the system was designed to behave that way in the first place.
But generating and updating records is only half the problem. The other half is making that accumulated reasoning findable - by engineers who don't know what to search for, and by agents that need prior human judgment before proposing changes. That's where the query layer comes in.
Making the knowledge base queryable.
Once you have a body of Decision Records accumulating across your repositories, PRs, and team sessions, the next question is how to make that reasoning retrievable - not just by engineers who know what to search for, but by engineers who don't know what they don't know, and by AI agents that need prior human judgment as context before proposing changes.
The right architecture for this is Retrieval Augmented Generation (RAG). The concept is straightforward: a pipeline ingests your decision records from wherever they live - your /decisions folders, merged PRs, your company wiki, architecture review transcripts - chunks them into retrievable units, generates vector embeddings, and stores them in a vector database. When someone (or something) asks a question, the system retrieves the most semantically relevant chunks and uses them to ground the response. The result is a query interface that finds "why did we choose not to guarantee delivery order?" even when those exact words don't appear in any document, because it's matching meaning, not keywords.
The pipeline can be triggered two ways, and the right choice depends on your team's size and record volume:
- Event-driven: the pipeline runs whenever a new decision record is merged, a PR with an ADR label is closed, or a wiki page in a designated space is updated. Records stay current with minimal lag. Good fit once you have consistent capture habits and a moderate record volume.
- On a timer: the pipeline runs on a schedule - nightly, or every few hours - and re-ingests sources wholesale or incrementally. Simpler to set up initially; the tradeoff is that very recent decisions may not yet be retrievable.
Either way, the pipeline is the bridge between capture and retrieval - the mechanism that transforms a collection of Markdown files and merged PRs into something queryable.
Two consumers, two different stakes.
For engineers, the RAG system surfaces as a chatbot or search interface: ask an architectural question in plain language and get an answer grounded in actual decision records, with citations. The value is discovery - finding reasoning you didn't know existed, especially when joining a team, returning to a service after time away, or trying to understand why a constraint exists before proposing a change. This replaces the experience of opening Confluence to find a page last updated three years ago by someone who has since left.
For AI agents, the value is more consequential. An agent working autonomously on code sees only what's visible in the implementation: the structure, the contracts, the present behavior. It cannot see why those choices were made, what alternatives were ruled out, or what failure modes are documented. By giving agents access to the RAG corpus as part of their context - surfacing relevant decision records before they propose changes to a service boundary or architectural contract - you ground their reasoning in prior human judgment rather than letting them derive everything from code inspection alone. The quality of that grounding depends entirely on what was captured. An agent reasoning from auto-generated code summaries is reasoning from its own prior outputs. An agent reasoning from narration-sourced decision records is reasoning from human intent.
This distinction - between a knowledge base built from human reasoning and one assembled from AI-generated summaries - is why the capture practices in this series matter. The RAG system is only as good as what goes into it.
Build toward this in stages:
- Start here (no platform investment): a
/decisionsfolder, a consistent naming convention, a lightweight index file mapping component names to records.- Add the pipeline: ingest your decisions folder and merged PRs into a vector store. Start with a timer-based trigger. Expose it as a simple chatbot for your team.
- Expand sources: add your wiki, architecture review transcripts, and postmortem records to the ingestion pipeline.
- Connect agents: surface relevant records as context for AI coding agents before they propose changes to documented contracts.
Each stage is independently useful. You don't need stage four to get value from stage one.
What kills this - and what makes it stick.
Most knowledge capture initiatives fail for one of three reasons:
- The artifacts live somewhere separate from where engineers work. The repo-based approach addresses this.
- The maintenance burden falls on individuals rather than the workflow. Automated PR-based update suggestions address this.
- The practice was introduced as policy rather than adopted because it was useful. This is a culture problem, and the only reliable solution is making the records genuinely valuable to the people who are supposed to maintain them - which is why the consumption layer matters as much as the capture layer.
The narration workflow helps with the third problem because it produces value immediately for the engineer doing it, not just for teammates six months later. If the only benefit is "future colleagues will thank you," the practice won't survive the next deadline.
When the Agent is Making the Decisions
The narration workflow described in Part two assumes a human who participated in a decision and needs to articulate it. That assumption is already weakening. As AI agents become more capable and organizations extend more autonomy to them - fewer human approval gateways, longer autonomous task chains, architectural changes made or proposed by agents rather than reviewed and guided by engineers at each step - the human may not be present for the decision at all.
This is where we're heading, and it's moving quickly enough that the infrastructure choices you make now will determine whether you can govern it. The decision record corpus you've been building - narration-sourced, versioned in your repository, queryable through semantic search - is exactly the memory layer that determines whether autonomous agents can operate with accumulated architectural context or without it. Agents with access to that corpus can ground their decisions in prior human reasoning. Agents without it are working from code alone, blind to the constraints and trade-offs that shaped the system they're modifying.
The challenge isn't that agents are making decisions. It's that agents operating on code alone make decisions without the context that human engineers accumulated over time: the rationale behind service boundaries, the failure modes already discovered and documented, the constraints that exist for reasons the code doesn't explain. An agent that refactors a service boundary may be making a locally optimal change to the code while violating an architectural constraint that was deliberate - and the only artifact that would have caught the conflict is a decision record the team never created.
There's also a compounding risk that's easy to underestimate. Without a structured memory layer, agents don't just make decisions in isolation - they make decisions that become the implicit context for future agents. An incorrect assumption made by one agent, unchallenged because no decision record contradicted it, can propagate through subsequent changes. The organizational knowledge drain this series has been describing accelerates when the decision-makers aren't human, because at least human engineers occasionally ask "wait, why did we do it this way?" An agent that doesn't surface its reasoning offers no equivalent checkpoint.
The direction of flow inverts - and humans become reviewers.
For human-driven decisions, the narration workflow runs human → artifact: a person who made a decision articulates it, an AI helps surface its assumptions, and the artifact captures the reasoning for future use. For agent-driven decisions, the flow needs to run agent reasoning → artifact → human ratification. The agent's decision trace - what it considered, what it chose, what assumptions it made - needs to be surfaced in a form that a human can review and either ratify or roll back.
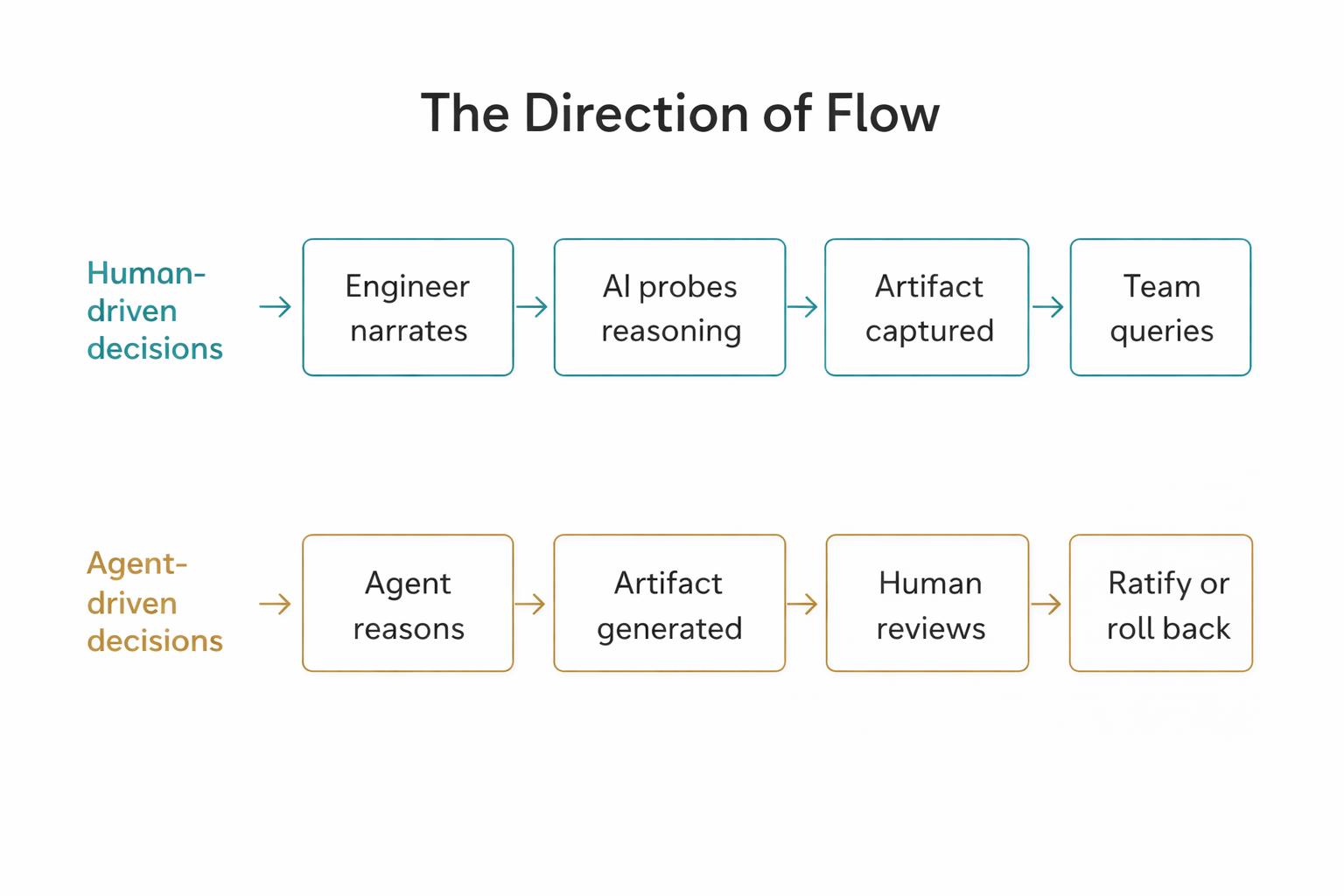
This means the PR review changes. The question shifts from "does this code do what it says?" to "did the agent's reasoning account for the right architectural constraints?" A test suite that passes is not evidence that the agent made the right architectural choice. The decision record - generated by the agent from its own reasoning, reviewed by a human steward - becomes the review surface that matters. Code review without decision review is an incomplete governance loop for autonomous agents.

What to build toward, and what to ask now.
The teams that navigate this transition well will have done two things in advance:
- Build the decision record corpus before they need it. A body of narration-sourced records representing the organization's accumulated architectural reasoning, queryable by the agents that will eventually need to ground their decisions in it. This is why the narration practice matters now, not later: the corpus has to exist before autonomous agents arrive.
- Establish the expectation that autonomous agents surface their decision reasoning in a reviewable artifact, not just code output.
The second point is something you can factor into tooling choices today. When assessing AI coding agents or autonomous development platforms, ask:
- Does this system surface decision reasoning in a form humans can review?
- Can it query an external knowledge base before proposing architectural changes?
- Does it produce a record of what it considered and what it ruled out, or only a record of what it did?
The answers vary significantly across tools, and they will matter more as autonomy increases.
The Staff+ stewardship model described earlier in this article takes on a different shape in an agentic context. The steward's job isn't just to ensure human decisions are captured. It's to review and ratify agent decisions, identify conflicts with prior records, and maintain the quality of the knowledge base that future agents will query. The role doesn't diminish as autonomy increases. It becomes the governance layer.
The Leader's Job
Cognitive drain doesn't announce itself. It won't show up in your velocity metrics, your deployment frequency, or your incident rate - at least not until the paralysis is already setting in. By the time a team realizes they can no longer make confident architectural decisions about their own system, the drain has been underway for months. The agentic transition accelerates that timeline: decisions that once happened over days now happen in a session, and the reasoning can evaporate before anyone thinks to capture it.
The practices across this series are designed for the period before that - when the metrics still look fine, when engineers are shipping confidently, and when AI-assisted development feels like pure upside. That's exactly when the hairline crack needs attention, because that's when fixing it is cheap.
Here's what to do next.
Engineering leaders:
- Introduce the keeper → steward conversation with your Staff+ engineers this week. Use the coaching language in this article. It's a 1:1 conversation, not a policy rollout.
- Define the three decision levels with your Staff engineers (introduced in Part two) and agree on what requires a formal record versus what lives in the PR. Clarity here is what makes the practice sustainable.
- Set the PR checklist expectation for Level 1 and Level 2 decisions: a decision record accompanies or precedes the merge.
- Start reading incident postmortems as comprehension signals, not just incident reports. How long does it take the team to form accurate hypotheses? That's your cognitive drain baseline.
- Start with what costs nothing: a
/decisionsfolder, a naming convention, and a PR checklist requirement. Build toward automated update suggestions when you have a Staff+ engineer who can own the workflow. Invest in semantic search when the record base is large enough to benefit from it. - When evaluating AI tooling: ask whether the system surfaces agent decision reasoning in a reviewable form, and whether it can query an external knowledge base before proposing architectural changes. Add these to your evaluation criteria now, before autonomy increases.
Staff+ engineers:
- Identify the Level 1 contracts in your domain (the highest-impact service boundaries and architectural decisions, as defined in Part two). If they don't have records, write them first - that's the immediate gap to close.
- Run one pre-mortem with your team before your next major project kicks off. Use it to surface what isn't documented yet.
- The next time you make a Level 2 decision (a significant design choice with cross-team impact), use the narration workflow before merging. Treat it as a reference implementation for your team.
- Own the quality of the decision record corpus in your domain. When an agent proposes a change that touches your service's contracts, your job is to evaluate the reasoning behind the proposal, not just the code it produced.
None of these practices are designed to slow down your team's velocity - they fit into work that's already happening, at PR time, in 1:1s, at retrospectives. The goal is just to ensure that what your team is building doesn't gradually become something nobody fully understands - a system that runs fine until the day it doesn't, and nobody can explain why.
The "what just happened?" question from that late-night coding session has an organizational version - the postmortem where nobody can reconstruct why the system was built the way it was, or the architectural review where the team's most experienced engineer can't explain the assumptions behind a key design decision. We lived that version two years after Bill left, standing in front of a constraint nobody could explain anymore. At scale, there's no chat window to scroll back through. These practices are how the answer gets written down before anyone has to ask.
Key Takeaways
- Artifacts live in your repository, not a wiki. Records version with the code, surface in PR reviews, and integrate naturally into existing workflows. The Confluence graveyard is an architecture problem, not a discipline problem.
- Staff+ engineers shift from keeper to steward. The goal isn't memorizing every detail - it's ensuring the reasoning behind significant decisions is captured in a form teammates can query, and that agent-proposed changes are evaluated against prior reasoning, not just whether tests pass.
- The PR intelligence pipeline is the automated bridge between capture and currency. AI-processed session recordings and transcripts generate draft record updates as PRs; the pipeline flags when merged changes touch documented contracts and surfaces relevant records during review. Humans stay in the approval loop; the workflow does the maintenance work.
- A RAG pipeline is the architecture that makes decision records queryable at scale. Ingest from
/decisionsfolders, merged PRs, wikis, and transcripts; chunk, embed, and store in a vector database; expose as a chatbot for engineers and as grounding context for AI agents. The system is only as good as what goes into it - records built from human reasoning ground agents in human intent, not their own prior outputs. Build it in stages: folder and index first, then the ingest pipeline, then connect it to your agents. - Code review without decision review is an incomplete governance loop for autonomous agents. An agent's decision trace - what it considered, what it chose, what assumptions it made - needs to surface in a form humans can review and ratify or roll back.
- Build the corpus before autonomous agents arrive - and build the pipeline to make it queryable. Agents operating on code alone work blind to the constraints that shaped the system. The decision record corpus is the memory layer that grounds agent reasoning in prior human judgment. The staged path: start with a
/decisionsfolder and naming convention, add the automated PR update pipeline, then the RAG query layer. It has to exist before you need it.