
Part two of a three-part series. Part one: Cognitive Drain: The Silent Risk of AI-Assisted Development. Part three: Building the Memory Layer: Scaling Decision Capture Across Your Organization.
After an intense vibe coding session that went late into the night (heavy users of AI coding agents will know what I'm talking about), I felt a sense of accomplishment. My AI partner and I had solved complicated architectural challenges, made pivots, and navigated incorrect assumptions with grace (and occasional fumbles that were good learning experiences). The final product was something I could be proud of, but the process - all the rapid back-and-forth ideation and problem-solving with AI - left me exhausted. At the conclusion of this coding session, my first thought was "what just happened?" The answer was captured in the chat window, but localized to the session (the stateless, ephemeral session) and would vanish if it wasn't materialized somewhere accessible.
That session was mine. But as an engineering leader, multiply that experience across every engineer on your team and the picture shifts. "What just happened?" isn't just something engineers experience at the individual level. It's something that accumulates on each team daily, as the reasoning behind dozens of decisions evaporates with every closed session window. Scale that across multiple teams and engineers at an organization, and you have the Cognitive Drain Problem I laid out in Part one of this series. As leaders, our job is to interrupt it before the pool of shared system knowledge is too shallow to dive in.
Cognitive drain, or cognitive debt, is an issue that is just appearing on the radars of engineering leaders, but the sense of urgency behind preventing it varies widely. For many leaders, the metrics look fine and there's no obvious moment to stop and build better practices, so there is a strong temptation to wait. Cognitive drain feels like the same documentation problems we've always had, the ones that keep getting added to the tech debt to-do list the team will get to "eventually." What does intervention look like when the problem is invisible and the velocity is high?
Treating cognitive debt like ordinary tech debt is the wrong model. While documentation gaps are visible, cognitive drain isn't. Conventional responses like "document your decisions," "run architecture reviews," or "require AI-generated PR summaries" don't reach the root cause. They produce Confluence graveyards, overhead without traction, and AI-generated artifacts that capture what was built without capturing why. By the time cognitive drain shows up in your metrics, it's already been compounding for months.
The cost of waiting to fix the leak is too high. Leaders need to intervene while velocity is high and context is still fresh. The intervention doesn't require a new process or a dedicated platform initiative. The practices in this article slot into work your team is already doing: PR reviews, 1:1s, retrospectives. This article includes steps for using your existing artifacts for diagnosing how far the drain has progressed, a decision capture framework precise enough to hand to a Staff engineer this week, and the narration workflow to coach into your team's practice.
What to Measure First (Without Adding Overhead)
Before building any new practice, it's worth establishing whether you actually have a problem and how far it's progressed. Engineers don't need more surveys, more reporting, or more overhead (and neither do you). Both signals here surface from work your team is already doing, or can be introduced as lightweight additions to existing team rituals.
Cross-component PR annotation requires no additional instrumentation - the signal is already in your PR review workflow. When an engineer makes a change that crosses a service boundary or touches a shared contract, look at whether they explain the dependency reasoning in their own words or let an AI summary stand alone. The former is evidence of maintained understanding. The latter, as a pattern across multiple engineers and multiple PRs, is a signal worth raising.
The coaching instruction is simple: tell your engineers to write the dependency reasoning before running the AI summary, not after. The AI summary can accompany their explanation, but it can't replace the act of forming it. The PR intelligence pipeline described in the next article in this series automates detection of which PRs cross documented contract boundaries - making the observation easier to sustain at scale without reading every PR individually.
Decision quality under pressure is the most diagnostic signal available, and you're already collecting it in incident postmortems. The pattern to look for isn't whether the root cause was identified, but how long it took engineers to form accurate hypotheses about which component was responsible and why. One version of the problem is easy to spot: the same engineer's name appearing on every postmortem as the person who identified the source and the fix. That's the bus factor made visible. The subtler version - the one that signals early-stage cognitive drain - is an increasing time to diagnose, driven by uncertainty about systems engineers have been working in for months. Engineers in the war room saying "let me read through the code and figure out how this works" is the tell. Teams with healthy shared knowledge converge quickly on plausible explanations, but as shared knowledge drains, that convergence takes longer and longer. Start reading postmortems as comprehension signals, not only as incident reports.
Pre-mortem exercises apply the same diagnostic logic before a problem occurs. Running a regular system-level pre-mortem surfaces cognitive drain as a signal while simultaneously building the shared operational understanding that prevents it from deepening. The prompt is simple: pick a service, name a plausible failure mode, and ask the team to walk through how they'd diagnose and recover. "Walk me through how you'd debug [service] if [specific failure mode] happened." This is particularly effective with newer team members in the room because it creates an opportunity for experienced engineers to narrate their mental models out loud. Gaps surface in a low-stakes environment before they show up in a real incident, and the quality of the answers is more diagnostic than any survey. If the level of cognitive drain is high, pre-mortem exercises will feel clunky and the team will probably come to the conclusion on their own that they need to learn their own systems better. Think of it as a lightweight Disaster Recovery (DR) dry-run: the same diagnostic value, without waiting for a real incident to run it.
A key note for leaders on observing these signals: attach them to work that's already happening wherever possible. The pre-mortem works best as a replacement for an existing meeting slot rather than an addition to the calendar. The PR annotation coaching requires no meeting at all. AI tools can also help surface trends in the underlying data: time to diagnose and restore, bus factor signals, and risk patterns in incident reports.
A Framework for What Actually Belongs in a Decision Record
If your team already uses Architecture Decision Records, the practice introduced by Michael Nygard in 2011 and now common in mature engineering organizations, the framework below extends rather than replaces that practice. The standard ADR captures the problem, the options considered, the decision, and its consequences. What's different here is both the granularity model (what gets a formal record versus what lives in the PR) and a field that most ADR templates omit: the signals that would indicate this decision should be revisited. That gap matters more now when a decision that used to unfold over days of back-and-forth can happen in a single afternoon session and still feel complete.
The biggest and most important difference in this framework isn't structural. It's about how the record gets generated. Standard ADR practice doesn't prescribe a capture method; most teams write records after the fact, from memory, or skip them entirely under deadline pressure. The narration workflow in this article is built on the principle that the direction of flow determines whether a record is a genuine diagnostic practice or just more documentation overhead. AI-generated summaries of code produce artifacts that describe what was built. Human narration - with AI as structured interviewer rather than ghostwriter - produces artifacts that capture why, including the alternatives ruled out and the assumptions the decision depends on. Teams already using ADRs will recognize the format; the workflow is what makes them worth having.
Your team needs a shared model for what belongs in a knowledge capture practice - because "document your decisions" is advice that collapses without a granularity framework. The instinct to capture everything produces the same outcome as capturing nothing: the artifacts accumulate faster than anyone maintains them, retrieval becomes impossible, and engineers stop consulting them. A 2024 action research study presented at the European Conference on Software Architecture found that teams lacking structured decision documentation faced significant friction in onboarding and architectural reasoning. The study found that introducing ADRs improved both areas, but only when paired with clear guidance on what to capture at what granularity.
Three levels, in descending order of importance:
Level 1 - System contracts. The interfaces, data contracts, and integration patterns between services or major components. Identify who owns the contract, what guarantees it makes, and what the failure modes are. Change frequency: low. Consequence of leaving undocumented: high. Everything at this level gets a formal, versioned record. Tools like OpenAPI and Swagger document the shape of a contract - endpoints, schemas, status codes. They don't capture the reasoning behind it: why it's designed this way, what guarantees it actually makes to callers, and what failure modes exist beyond the HTTP spec. That's what a Level 1 record adds. Think of it as the minimum an engineer must own regardless of how the implementation was written or in what language. An engineer who can't explain what a contract guarantees and what breaks it doesn't have enough understanding to safely work with the system - even if they can read every line of code it produced.
Level 2 - Design decisions with lasting consequence. Choices that constrain future options like selecting an eventual consistency model, deciding a service boundary, or choosing a data storage pattern for a specific use case. Sometimes these decisions are too small to make it into an RFC, but they're too consequential to leave implicit. This level is the primary target of your capture workflow, and it's where most cognitive drain originates: these decisions get made quickly under AI-assisted velocity and never recorded.
Level 3 - Implementation rationale. Why a specific, localized approach was chosen for a particular implementation. If the decision involved meaningful trade-offs between alternatives or is large enough to warrant stakeholder review, it belongs in an RFC, not here. What belongs at Level 3 is the smaller stuff: why this pattern over that one, why this library, why this error handling approach. This belongs in structured PR descriptions where it's searchable and extractable for automated pipelines, and occasionally inline comments for logic too localized to surface anywhere else. It feeds into the broader record over time but isn't the entry point.
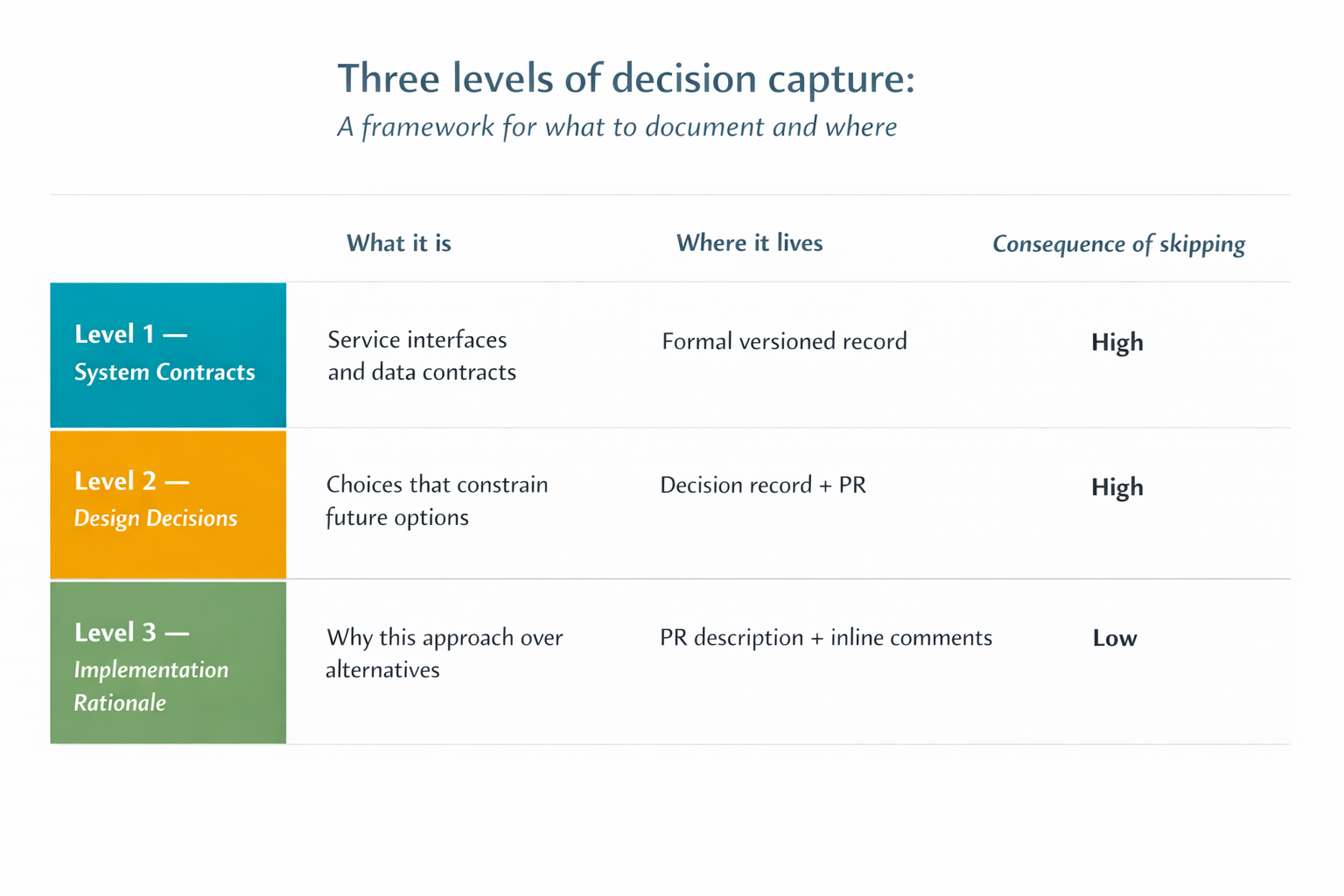
The instruction to give your Staff+ engineers: if you're making a decision that will constrain someone else's options six months from now, it's Level 1 or Level 2 and needs a record. If it only affects the current implementation and leaves future options open, the PR is sufficient.
Every Level 1 and Level 2 record should include a revisit signals field - the observable conditions that would indicate this decision should be reconsidered. This is the field most ADR templates omit, and it's where most records go stale silently. Examples: "revisit if the order service's read-to-write ratio changes significantly" or "revisit if a second team needs to consume this contract." Pair it with a concrete revisit date - a calendar block for the team, not just a note in the record. Observable conditions tell you when something has changed; the date ensures the decision gets reviewed even when nothing obvious has triggered it. The two together are what make a decision record a living document rather than a timestamp.
The Decision Narration Workflow
When I homeschooled my children using classical education methods, one of our core practices was narration: after reading or listening, each child would retell what they had just heard in their own words without looking back. The technique traces back to Roman rhetoricians like Quintilian and was central to Charlotte Mason's educational philosophy. It works for a simple reason: the act of retelling forces you to reconstruct understanding rather than just recognize it. Passive review leaves gaps you don't notice. Active narration surfaces them before you move on. I still use this technique to understand whether I understand something well enough to explain it.
The same mechanism is at work here. This is the practice - specific enough to introduce in a 1:1 with a Staff engineer this week and concrete enough that any IC on the team can start using it today.
The core principle is direction of flow: knowledge capture only works when it moves from human understanding into artifacts, not when AI generates artifacts from code. This is the cognitive offloading problem made concrete: when engineers delegate reasoning to AI, they disengage - and disengagement erodes critical thinking. A 2025 study confirmed this isn't theoretical: frequent AI tool use showed a measurable negative effect on critical thinking, with the mechanism being exactly what you'd expect. The less thinking you do, the less capable you become of doing it. The narration workflow is deliberately designed in the opposite direction, keeping the engineer as the one doing the reasoning while AI serves as a structured interviewer, not a ghostwriter.

What You're Coaching Your Engineers to Do
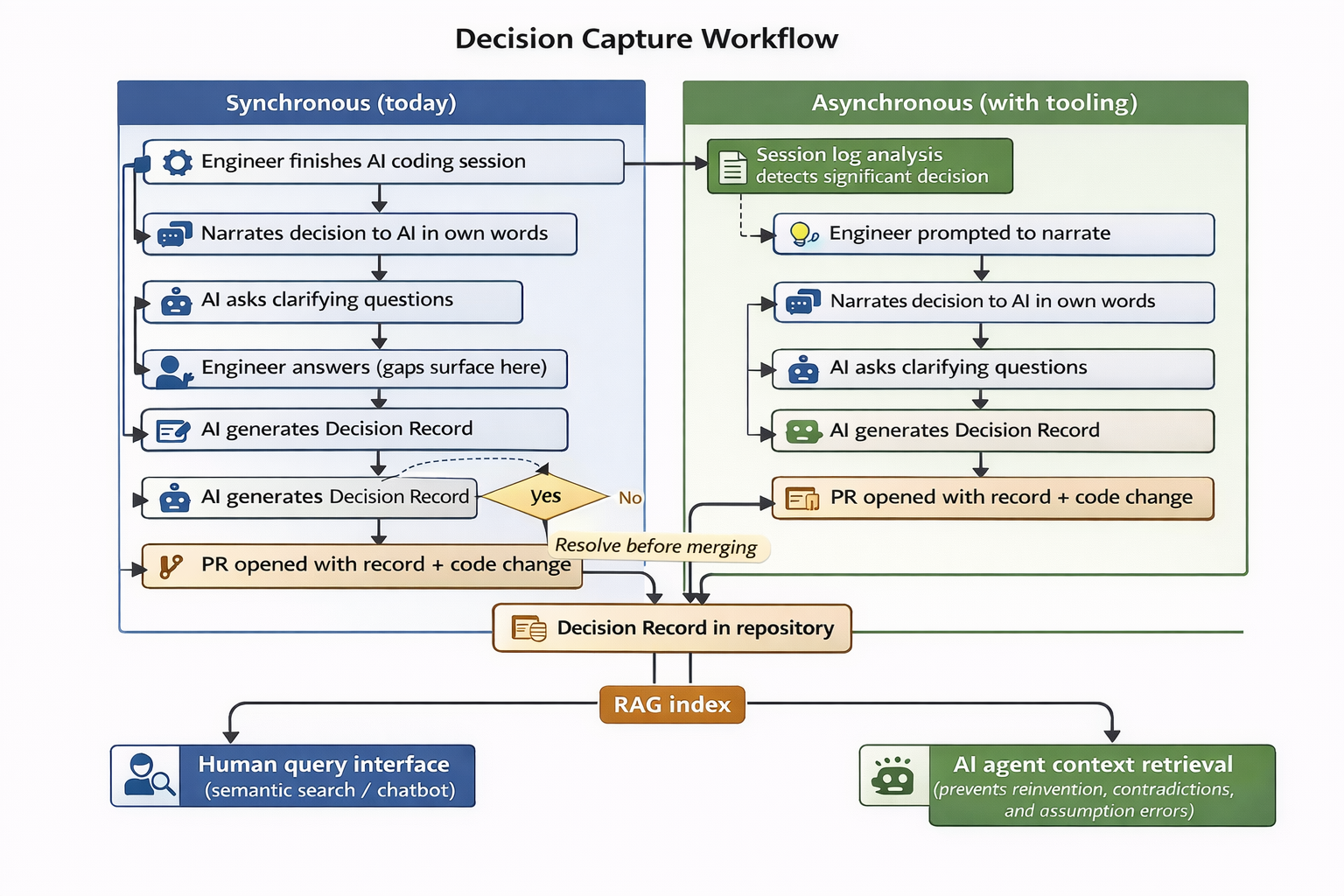
Here's the specific workflow that you or a Staff+ can introduce to the team - a mini-retro on the decision, run inside the same chat session before the engineer closes the window. The scenario: an engineer has just spent 90 minutes working through an architectural choice with an AI coding agent. They've committed to an approach that ruled out two alternatives. Before they close the window:
In the chat session, narrate the decision in your own words: the problem you were solving, the options you considered, what you ruled out and why, and why you landed where you did. Not "here's what we built" - that's already in the code. The reasoning is what evaporates.
If narrating cold is hard, start here instead. Send: "Ask me about this decision one question at a time - start with: what problem were we solving?" Answer each question before the AI moves to the next. The structure is the AI's job. The reasoning is yours.
Ask the AI to probe your reasoning. Prompt: "Ask me clarifying questions about this decision - what assumptions it depends on, what would have to be true for a different choice to be better, and what the failure mode is if an assumption is wrong."
Answer the questions. If you can't answer one, that's not a failure - it's a gap to fill before merging. Ask the AI to give you feedback on your responses and to use the session context to identify anything that was missed. It's like a 1:1 deep-dive with a colleague: no such thing as a stupid question, and no shame in saying "I don't recall why we chose A over B."
Ask the AI to generate a Decision Record using your team's template. Review it against your narration: it should reflect your reasoning, not invent it or summarize the code.
Open a PR with the record alongside your code change.
The secondary benefit of this workflow is diagnostic - and this is what makes it worth coaching, not just mandating. An engineer who narrates a decision and can't answer the AI's clarifying questions is discovering gaps in their own understanding in a low-stakes environment. That's cognitive drain surfacing before it becomes an operational problem, and it surfaces to the engineer, not just to you. Most engineers are most comfortable starting this mini-retro individually with AI, but it can also scale to a pairing or mobbing exercise when there's adequate psychological safety and a learning mindset on the team.
What good looks like from where you sit: you're reviewing a PR that crosses a service boundary. You open the description and the engineer has already answered the question you were about to ask - they've named the alternatives they considered, stated what ruled them out, and flagged the assumption the decision depends on. You close the PR without leaving a comment about the missing context. That's the narration workflow working. The absence of that description - an AI summary where the reasoning should be - is the signal it isn't.
When decision records accumulate at scale, they become something more than documentation. The patterns across them are worth analyzing: which systems generate the most constraint-driven decisions, where technical debt is quietly shaping architecture, which assumptions keep appearing across unrelated choices. That's where the next article picks up.
Before Engineers Touch Systems They Don't Own
At a previous company, I watched firsthand how a large reorg left teams owning systems they didn't write and weren't comfortable maintaining. Support tickets missed SLAs not because engineers lacked skill, but because nobody felt safe making changes to unfamiliar code, and the paralysis was organization-wide. This is a practice I wish I'd had then. It's also worth introducing proactively for cross-team changes and to reduce knowledge silos before a major ownership change event.
Before an engineer proposes a change to a system they don't primarily own, coach them to spend fifteen minutes letting an AI model interrogate their understanding of it first.
The prompt: have them ask the AI to probe their mental model of that system - how it works, what assumptions its design depends on, and where their understanding breaks down. Passive engagement with AI-generated code reliably produces what a 2024 theoretical review in Cognitive Research: Principles and Implications calls "illusions of understanding." AI assistance accelerates skill decay while simultaneously preventing engineers from recognizing it, leaving them with high confidence and declining competence. Active interrogation is the antidote.
Frame it to your engineers not as a gatekeeping requirement but as a useful step. The gaps the AI surfaces are exactly the questions worth answering before touching a service boundary, not after. The engineer who can't explain why a contract was designed the way it was before proposing to change it is the one who creates the incident two weeks later.
The practices in this article - reading your existing artifacts for cognitive drain signals, giving your team a shared framework for what deserves a record, and coaching the narration workflow into your team's practice - are designed to start this week with no platform investment. What builds on top of them - the infrastructure for keeping knowledge alive at organizational scale, the Staff+ stewardship model, and the governance framework for when AI agents stop being assistants and start making architectural decisions - is the subject of the next article in this series: Building the Memory Layer: Scaling Decision Capture Across Your Organization.
Key Takeaways
- The coaching instruction that changes PR reviews. Tell your engineers to write the dependency reasoning before running the AI summary, not after. The signal that cognitive drain is setting in is a pattern of AI summaries where the reasoning should be.
- Three levels, one shared vocabulary. Give your team the framework: Level 1 system contracts get formal versioned records, Level 2 design decisions with lasting consequence are the primary capture target, Level 3 implementation rationale lives in the PR. Without this shared model, "document your decisions" collapses under its own vagueness.
- The narration workflow is a mini-retro, not a policy rollout. Introduce it to a Staff engineer this week. The five steps take fifteen minutes and produce a Decision Record that captures why - not an AI summary of the code.
- If narrating cold is hard, give engineers the on-ramp prompt. "Ask me about this decision one question at a time - start with: what problem were we solving?" The structure is the AI's job. The reasoning stays with the engineer.
- Every decision record needs a revisit signals field. The observable conditions that would indicate the decision should be reconsidered. Most ADR templates omit it. That's why most records go stale silently.
- Coaching the cross-system probe prevents incidents - especially after reorgs. Before an engineer proposes a change to a service they don't primarily own, have them let an AI interrogate their understanding of it first. The gaps it surfaces are worth finding before the PR, not after the incident.