
How a red-green-retro cycle turned AI coding agents from unpredictable to reliably autonomous - and what every engineering leader needs to put in place before they scale it.
Throughout my career I've worked inside organizations with widely varying views on test-driven development. Some treated it as a founding principle - "this is how we work", while others kept it as a preference - "use it if you want." Regardless of the official company policy on TDD, I've mostly seen it used inconsistently, depending on the engineer, the deadline, or the legacy code they happened to be modifying. I have to admit that even as an engineering executive, I only made team agreements around "every PR should include appropriate tests" without prescribing if the code or the test should be written first.
Now with the rise of agentic AI coding, I have a new perspective on TDD.
When a human developer skips writing tests first, the cost is localized: some rework, some coverage debt, a bug caught in QA. With AI agents, the problem is structural. As agents take on more work in parallel, human review of every line of generated code isn't governance - it's a bottleneck in a different place. Real governance at scale comes from contracts: between requirements and code, between what the system is supposed to do and what it actually does. Tests are those contracts. They're the mechanism that keeps agents honest when humans can't read everything.
AI is genuinely excellent at writing tests. Give an agent a piece of code and it will generate hundreds of cases with near-complete coverage. But those tests describe what the code currently does, not what it was designed to do. An agent that implements a feature and then writes tests for it is validating its own assumptions. The tests pass and the coverage looks healthy, but the functionality may still be wrong - and you have no systematic way to know.
I built ai-radar - a personal content digest - as deliberate research: a controlled environment where I could find out where a fully AI-assisted development workflow breaks before recommending it to teams where failure is expensive and adoption is political. A workflow where AI agents plan the work, write the tests, implement the code, review the PRs, and flag decisions they can't make alone. Where I function as the architect and the approver, not the implementer.
This is what I found - but first, a quick look at TDD's history, because the gap between how it's supposed to work and how it's actually practiced is exactly what makes agentic AI raise the stakes.
TDD: A Brief History and a Telling Gap
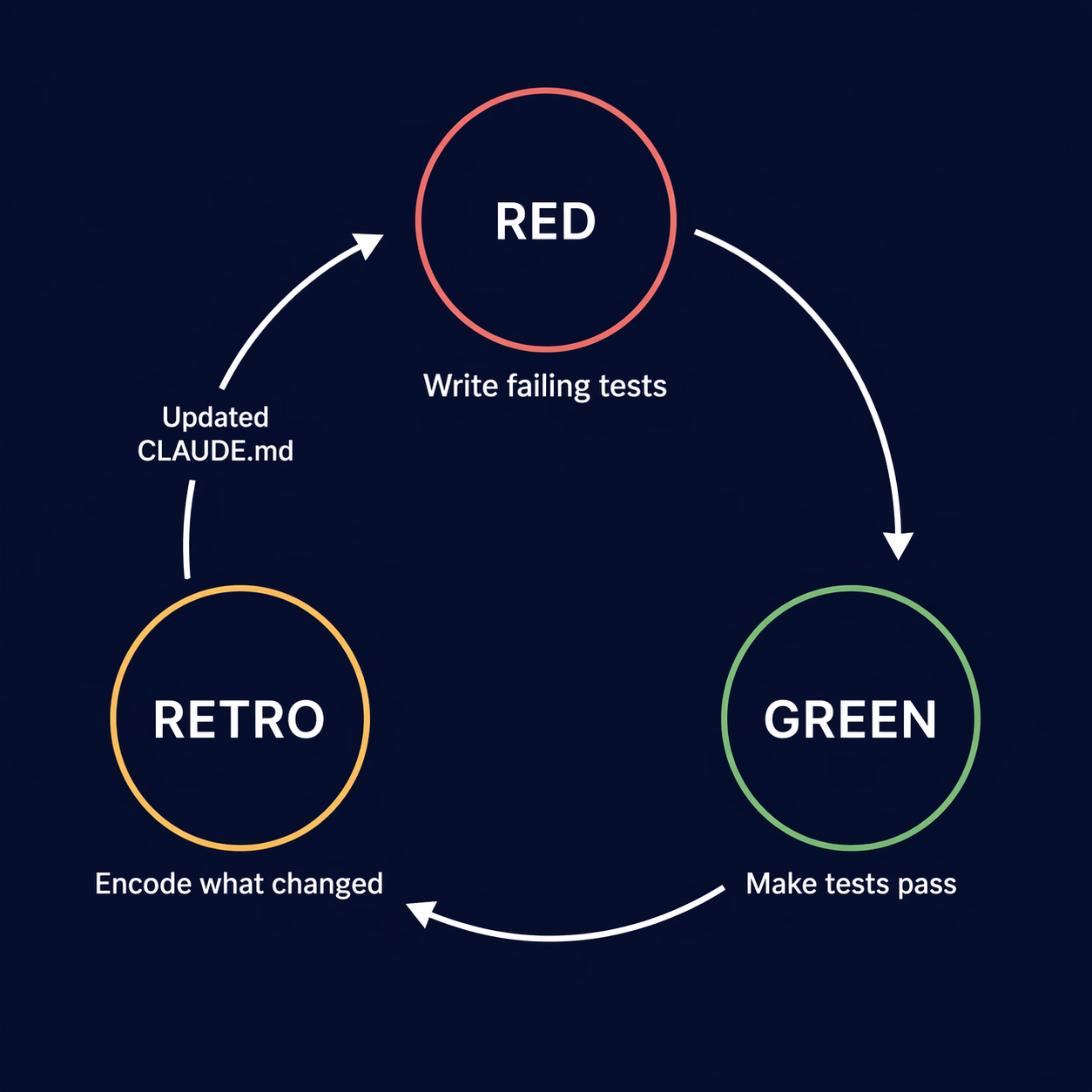
For anyone not steeped in XP history: test-driven development follows a three-step cycle - write a failing test first, write just enough code to make it pass, then refactor. Red, green, refactor. The test always precedes the implementation.
Kent Beck formalized TDD in the late 1990s as a core practice of Extreme Programming, predating the Agile Manifesto by several years. He is characteristically precise about his own role - he calls himself a "rediscoverer" rather than an inventor. Test-first thinking has older roots: researchers have documented that NASA's Project Mercury in the early 1960s used short, time-boxed iterations where independent testers wrote tests against requirements before programmers implemented features. Beck encountered something similar in early programming literature and built on it. His SUnit testing framework for Smalltalk appeared in 1994; JUnit followed in 1997; the formal methodology solidified from there.
The adoption picture is where it gets interesting. A 2020 survey found that 41% of developers said their organizations had "fully adopted" TDD - but only 8% said they actually write tests before code at least 80% of the time, which is the actual definition of TDD. That gap between claimed adoption and real practice is one of the largest in software development. Most teams end up writing tests after the fact, selectively, or not at all.
The research on outcomes is consistent regardless. A study of four IBM and Microsoft engineering teams published in Empirical Software Engineering found pre-release defect density dropped 40–90% on TDD projects, with an upfront development time increase of 15–35%. The teams generally considered the tradeoff worth it - reduced maintenance costs more than offset the slower start.
That's the baseline going into the AI era: TDD has solid evidence, genuine practitioners who swear by it, and a large population of teams that nominally use it while rarely writing a test before the code it tests. Which made it a reasonable candidate for the "optional" column - until you put AI agents in the loop.
Why I Built This Personally First
There's a version of AI development adoption that I see fail repeatedly: a leader reads about AI coding agents, gets excited, delegates the rollout to a staff engineer, and six months later has a team that either over-relies on AI in ways that produce untestable code, or under-uses it because the process never got traction. The leader is too far from the execution to diagnose which failure mode they're in, and too far from the tooling to ask the right questions.
Before I can ask a staff engineer to own this infrastructure - the briefing documents, the hooks, the ticket structure, the retro cadence - I need to understand it at the level of where it breaks. What failure modes does it produce when a component is missing? What does an under-specified autonomy boundary actually cost? What does a test suite that looks complete but has a gap in the contract actually look like in production?
Personal projects are the right environment for this research because the blast radius of failure is zero. When a bug ships in ai-radar, I'm the only one affected. When a process decision turns out to be wrong, I fix it without a team waiting on me. The constraints are real - I'm working in a real codebase with real dependencies and real LLM APIs - but the stakes are low enough to run experiments deliberately.
What I'm describing in this article is the output of that research. These are practices I've stress-tested personally and now have enough confidence in to recommend at organizational scale.
Two things surprised me. First: the mechanical enforcement infrastructure was easier to get right than I expected - once hooks are in place, agents stay in line. The most instructive finding was how much agents catch when reviewing each other's work - a fresh reviewer in a separate session, reading only the spec and the test PR, consistently flagged gaps the author agent missed. Second: the retro turned out to be the highest-leverage practice in the entire workflow, which I didn't anticipate going in. The value went beyond continuous improvement of the workflow. It created space for me to ask questions about decisions, reducing cognitive debt and allowing time for reflection. Both findings have direct implications for what to prioritize when you roll this out to a team.
The Workflow at a High Level
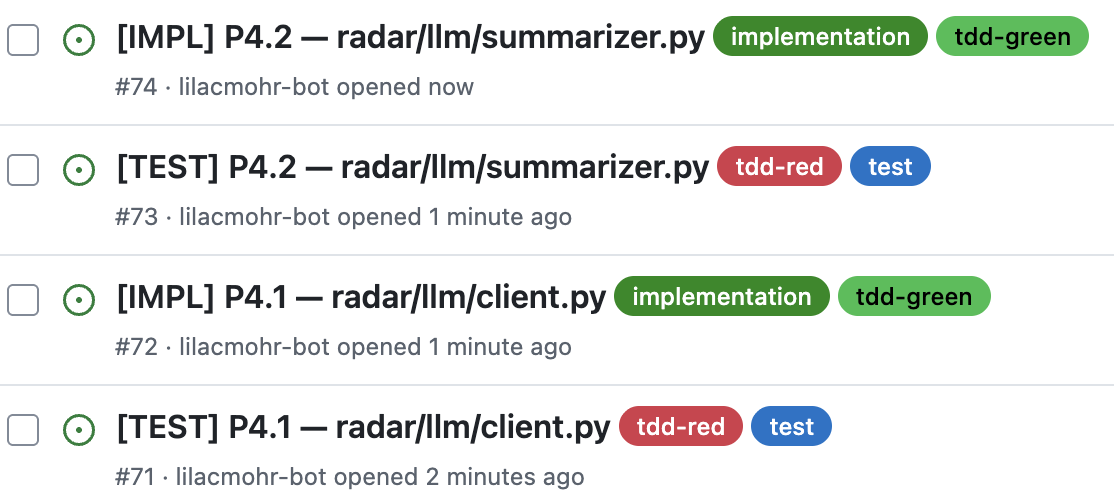
After the spec clears a quality threshold - scored across multiple dimensions and reviewed by multiple specialized AI reviewer personas, a process I cover in detail in I Had 9 AI Agents Review My Spec - I give it to an AI agent and ask it to break the work into phases - cohesive groups of functionality with clean dependencies between them. Each phase becomes a sequence of ticket pairs: one [TEST] ticket, one [IMPL] ticket, always in that order.
The structure is intentional. The test ticket is always created first and the implementation ticket is never opened until the test file is reviewed and merged into the feature branch. Red before green with no exceptions.
The separation matters beyond ceremony. An agent that writes tests and then implements in the same session already knows where it's going - the tests it writes will fit the implementation it's planning, not necessarily the requirements. Separate sessions break that loop: the test agent commits to a contract before the implementation agent exists.
Here's what each ticket type contains, and why:
[TEST] - Write the tests. Make them fail.
The test agent gets: the module to test, the spec section it implements, the pipeline context (what stage this is, what data type comes in, what comes out), the happy path behaviors, the failure cases, and an explicit instruction: do not write any implementation code.
The resulting PR has one job: make the tests red. Every test in the file should fail - not because of syntax errors, but because there's no implementation yet to satisfy them. This PR is reviewed by a second agent in a fresh context. That reviewer's job is specifically to ask two questions: What tests are missing? and Does each test actually verify what it claims to verify?
This is the step most teams skip. A test that always passes regardless of implementation behavior is not a test - it's documentation that happens to live in a test file. A fresh reviewer, reading only the spec and the test PR, will catch these in ways that the author, who knows what they intended, cannot.
[IMPL] - Make the tests green.
The implementation agent gets: the test file, the spec section, the public interface it must expose, and a single clear instruction: make the tests pass. Do not change the tests.
"Make the tests pass" defines the correctness bar, not the implementation quality bar. The test file is the executable contract - the agent must satisfy it, but satisfying it doesn't mean the implementation is good. An agent can pass every test with code that's fragile, inefficient, or structurally wrong. That's why the implementation PR review matters: it's looking for spec alignment, code quality, and anything the tests don't cover. If an agent needs to modify a test to make the implementation work, that's a conversation - not a shortcut. The test file was reviewed. The contract was agreed upon. Changing it without discussion defeats the purpose.
The Infrastructure That Makes It Reliable
The workflow above sounds clean on paper. What makes it reliable in practice is the layer underneath it - the encoded contracts that ensure an agent behaves consistently across every session, not just when it happens to remember.
The agent briefing document. Every agent that touches the codebase reads CLAUDE.md at the start of every session. It's the first thing in context. (The filename is specific to Claude Code - the same pattern applies to any agent-capable tool. The name of the file matters less than its function.) The document answers seven questions: what this project does, what the architecture is, when the agent should act versus surface a decision, what the code standards are, how failures should be handled, what the testing requirements are, and what "done" means. Keep these instructions tight and unambiguous. Agents follow concise, direct instructions more reliably than exhaustive ones - a bloated briefing document doesn't add coverage; it dilutes it.
The key section is the autonomy boundary. What can the agent decide independently? What requires a human? Under-specified autonomy is one of the most expensive mistakes in AI-assisted development. An agent with no guidance will either over-check-in (constant interruptions, losing the productivity gains you set out to capture) or silently make architectural choices that compound across tickets. Getting this boundary explicit and encoded - not just communicated verbally - is worth the hour it takes.
Hooks. The main distinction between a briefing document and a hook is this: instructions are advisory, hooks are guarantees. Hooks are shell commands that fire automatically on agent events - after a file is edited, before a task completes. An agent can forget an instruction, misread it, or decide it doesn't apply. A hook runs regardless. This is the difference between a process that works when agents are behaving well and a process that works mechanically.
Before I had hooks in place, I spent a disproportionate amount of time in a loop I hadn't anticipated: agent implements, I try to commit, pre-commit hooks fail, I hand the errors back to the agent, it fixes them partially, repeat. The agent couldn't get code committed without passing those checks - but it also couldn't run them itself. That left me as the relay: catching failures, surfacing them, waiting for fixes. Hooks ended that loop. Now the agent runs checks automatically after every file edit, sees the output, and self-corrects before I'm ever involved. It feels like accountability built into the process rather than delegated to me. The agent isn't just instructed to run checks - it's structurally unable to skip them.
Two hooks do the heavy lifting. A quality gate hook fires after every file edit - running lint, formatting, and type checking against every file the agent touches. Non-blocking: the agent sees the output and self-corrects. An agent that forgets to run lint will have lint run for it. A stop gate hook fires when the agent signals it has finished a task. It runs the full test suite. If any test fails, the agent is forced to continue - it cannot mark the task complete while tests are red. This enforces the TDD contract as a precondition for stopping, not as a reminder.
Issue templates. Each ticket type has a structured template that encodes the context the agent needs to start without a follow-up conversation. The [TEST] template requires: module path, spec section, pipeline position, input/output types, happy path behaviors, failure cases, edge cases. The [IMPL] template requires the same plus the public interface the module must expose. This isn't bureaucracy. It's the minimum information that prevents an agent from making an assumption in the first five minutes of a session that silently breaks something two phases later.
The importance of that targeted context is empirically supported. A March 2026 paper introducing TDAD (Test-Driven Agentic Development) found that giving AI agents procedural TDD instructions - write tests first, then implement - without providing targeted test context actually increased regressions above the vanilla baseline. The fix wasn't better instructions; it was richer context: a dependency map between source code and tests so the agent knows exactly which tests to verify before committing a patch. That structural context reduced regressions by 70%. The issue template is how this workflow encodes that context - not as a dependency map, but as the spec section, pipeline position, and interface contract the agent needs to write tests that actually verify the right thing.
A dedicated bot account - not your personal credentials. The issues in the screenshots throughout this article are opened by lilacmohr-bot, not by me. That's intentional, and I'd call it a prerequisite rather than a preference. The failure mode I see most often when teams start with AI automation: someone wires an AI agent to their personal GitHub account, gives it write access, and has it act as them. With a dedicated bot account, you can set branch protection rules that prevent a bot from approving and merging its own pull requests. Every PR the agent opens requires a human review before it merges. The agent can do the work. It cannot close the loop on its own.
The news stories about AI agents going rogue - deleting databases, taking down production - almost always trace back to the same root cause: an agent was given credentials with more authority than the human who set it up would have exercised themselves, and there was no structural check between the agent's action and the consequence. A bot account with restricted permissions and branch protections is that structural check. It doesn't rely on the agent behaving correctly. It enforces review as a precondition for merge, the same way the stop gate hook enforces green tests as a precondition for task completion. Set up the bot account before you wire anything to your repository - it's one of the few things in this workflow that's genuinely hard to retrofit.
The DECISION Issue: How Agents Ask for Help
When an agent hits a decision point, it always creates a [DECISION] issue - the decision is captured regardless of what happens next. What varies is whether the agent proceeds. If it has enough confidence to make the call itself, it continues implementation and records the decision it made in the issue. If the decision is blocking - structurally different code depending on the choice, or a tradeoff the agent doesn't have enough context to evaluate - it stops and waits for a human to weigh in before continuing.
The format is specific. One sentence describing the decision. Two or three options, each with concrete consequences: what code it affects, what the tradeoff is, what the downstream impact would be. A recommendation, with reasoning. The agent makes a case; the human makes the call when it matters. This keeps the human in the decision loop without creating constant interruptions for choices the agent can confidently resolve itself - and it means every decision, made autonomously or not, is visible and reviewable during the PR.
As Head of Engineering at Pluralsight, I created a decision log template that had very similar fields, but it was hard for engineers to build the habit of using it. With AI, this decision capture happens without the context-switching cost of stopping to document. I cover how this pattern scales across teams and feeds into an organizational memory layer in Building the Memory Layer.
This pattern matters at the team level as much as the individual project level. Looking at my own data from ai-radar: across five phases of development, each phase consistently produced one to two DECISION issues regardless of how many IMPL tickets it contained. What varied wasn't the count - it was the nature of the decisions. Early phases surfaced architectural choices: data model structure, config shape, pipeline contracts. Later phases surfaced integration-specific problems: CLI testability patterns, function ownership across modules, edge cases the spec hadn't anticipated. The work got more complex and novel, and the decisions reflected that.
That's the signal worth tracking. The count of DECISION issues per phase is a proxy for the complexity and novelty of the work - not a measure of process failure. A phase with more decisions than usual isn't a problem. It means you're in genuinely new territory, or the spec has gaps that need to close before the agents can proceed confidently.
This framing matters for how you introduce this pattern to a team, because there's a real antipattern to guard against: engineers suppressing decisions to look productive. If the metric becomes "fewer decisions is better," agents will start making choices silently and engineers will stop surfacing architectural uncertainty. That's exactly backwards. The decision record is what shifts the human role from reviewing AI code after the fact to helping AI architect the right approach before implementation. A team with no DECISION issues isn't one where everything is clear - it's one where ambiguity is being resolved invisibly, and you won't find out how until something breaks.
Over time, resolved decisions feed back into the briefing document - and the questions agents had to ask humans become questions agents can answer themselves.
The Retro: Where the Process Gets Better
This is the step I don't see documented anywhere else, and I think it's the highest-leverage practice in the entire workflow.
When a phase of work is complete - a cohesive group of related tickets - I run a retrospective with the implementation agent. The retro is a structured conversation about what worked, what didn't, and what should change for the next phase.
I ask probing questions: Where did you have to make decisions that weren't covered by the instructions? What did you find yourself doing repeatedly that we could automate? Were there tests that were hard to write because the interface design made them hard? The agent has context on every decision it made and every friction point it encountered. That context disappears when the session ends. The retro captures it.
The outputs are direct changes to the CLAUDE.md, the issue templates, and the hooks - actual updates to the artifacts that govern the next iteration of work. The process gets better with each phase, not through a separate improvement initiative, but as a natural output of the work itself.
A concrete example: after the Gmail ingestion phase, a retro surfaced that test mocks were consistently five levels deep - service.users().messages().list().execute.return_value - on every test that touched the Gmail SDK. Not wrong. Not causing failures. But every test that needed Gmail was awkward to write and hard to read. The retro identified this as a design signal: if a mock is five levels deep, the code extracted the wrong unit. I added a rule to CLAUDE.md capping mock depth at three levels, and extracted _list_message_ids() and _get_message() as named helpers. The next phase's tests were noticeably cleaner - but the more important outcome was that the rule was now encoded. Future agents working in the codebase would hit the same constraint and extract the same way, not because they remembered the conversation, but because the rule was in the briefing document.
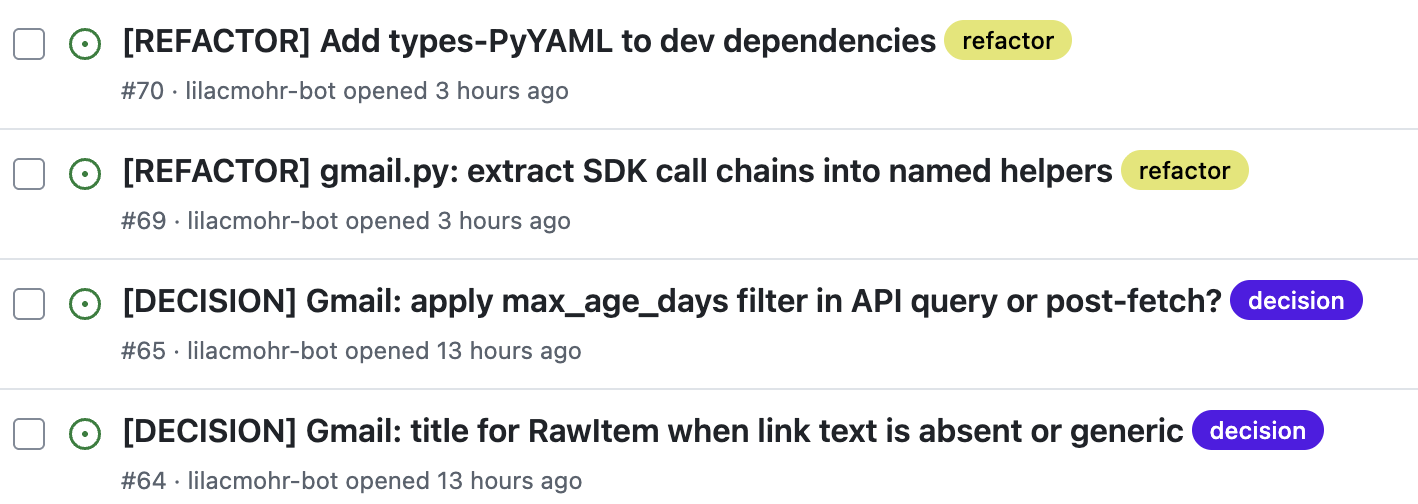
One specific output of retros: when I identify an area of code that should be refactored but isn't on the critical path - something worth doing eventually but not worth interrupting the current phase - the agent creates a [REFACTOR] ticket. The decision not to do it now is explicit. The work isn't lost. It enters the backlog while the context is fresh and the agent can write a ticket with enough detail that it can be picked up later without relearning the context.
This addresses one of the persistent frustrations with AI-assisted development I hear from engineering leaders: the refactoring never happens because it's never on the critical path. The retro makes it a first-class artifact.
What This Looks Like in Practice
For ai-radar, the workflow played out in phases documented in the GitHub issue history. Three moments illustrate the range of what the process catches - and what it almost missed:
A quality gate hook caught a type annotation mismatch immediately after a file edit, before the agent even finished the session. The fix was two minutes. If that mismatch had reached the stop gate it would have been buried in test failure output. If it had made it to the PR it would have required a review cycle to surface. The hook caught it for free.
An implementation agent hit an ambiguous decision about where in the pipeline to apply a cap on article count. The spec was silent. Two interpretations were structurally different: one was cheaper (cap early, fewer LLM calls), one was higher quality (score first, then cap). The agent created a [DECISION] issue with both options, the consequences of each, and a recommendation. The decision was made in five minutes. That same decision made silently - which is what happens without the pattern - would have required unwinding code from three pipeline stages.
The most instructive failure was one the test suite didn't catch at all. The synthesizer's prompt template labeled a section "🔍 Non-Obvious Insights." The parser looked for "🔍 Contrarian & Non-Obvious Insights" - the phrasing from the spec. Both files were written by AI agents. Both were internally consistent. Every unit test passed because they stubbed the LLM response rather than running the actual template through the actual parser. In production, digest.contrarian_insights was always empty. The bug lived in the contract between two files that never spoke to each other in tests. It was caught by a human reviewer reading both files side by side. The fix was a new rule: regression tests must import parser constants and assert their verbatim presence in the prompt template. That class of drift is now structurally prevented - not by better agents, but by tests that span the contract. And it's a reminder that human review isn't just a quality gate. It's the only thing that reads across the whole system at once.
That last failure is also the most useful thing to carry into a team rollout: the infrastructure doesn't eliminate human judgment, it redirects it. Hooks and test gates handle the mechanical. Cross-file contract failures and architectural drift are where your engineers - and your staff engineers in particular - still earn their leverage.
Scaling This to a Team
I built ai-radar greenfield, which makes certain things easier - you can establish the briefing document before the first line of code, set the hook infrastructure before there's anything to lint, and start with a spec that agents helped write. Most engineering leaders are reading this while managing a codebase that already exists, with existing tests (or not), existing conventions (or not), and existing technical debt. And unlike a personal project, they're also managing humans with existing habits, existing opinions about testing, and existing skepticism about process.
The workflow scales. The org change is harder than the technical change.
Who owns this infrastructure is a staff+ engineering question. The briefing document, the hooks, the ticket templates, the retro cadence - on a personal project, I own all of it. On a team, this needs a clear owner, and it should be a staff engineer, not the delivery team. This is not ticket-level work. It's the meta-layer that governs how ticket-level work gets done. A staff engineer who owns this well is doing something specific: keeping the briefing document accurate as the codebase evolves, refining the autonomy boundaries as the team's trust in the agents develops, and running retros that produce encoded changes rather than verbal agreements that disappear. Make this explicit in the role. Don't assume it happens by default.
Expect resistance in two specific places. Senior engineers are the most likely to push back, and for understandable reasons: they've been burned by process overhead before, they don't trust the test-first discipline because they're fast enough to hold the spec in their head, and they may feel the briefing document is constraining their judgment. The right response is not to mandate compliance - it's to give them the ownership described above. The engineers who resist the process most are often the ones who should be designing it. The other resistance point is teams under velocity pressure. The ticket-pair structure feels like overhead when you're behind. It's worth having the conversation explicitly: the overhead is front-loaded, and the alternative is rework that's much more expensive and harder to schedule.
Start with the briefing document, and make it accurate, not aspirational. A CLAUDE.md for an existing codebase takes longer to write well because you're documenting what exists, not what you're about to build. The autonomy boundaries, the quality gates, the architectural constraints - these should reflect reality. An agent that reads a briefing doc describing a different codebase than the one it's working in will fail in confusing ways, and the failures will be hard to diagnose. Spend the time to get this right before introducing agents to any codebase you care about.
Introduce ticket pairs for new feature work only. You don't need to retrofit TDD across the entire existing codebase. Every new feature - every enhancement, every new endpoint, every new service - gets a [TEST] ticket before an [IMPL] ticket. The new code grows test-covered. The existing code doesn't have to be migrated before you start, and attempting to migrate it all at once is a way to stall the initiative entirely.
Use the hooks as discovery, not enforcement. When you turn on a quality gate hook in an existing codebase, it will surface things: type mismatches, lint violations, formatting inconsistencies. Treat this as information about the state of the codebase, not as a list of things that must be fixed before you can proceed. The agent self-corrects on new code. The existing violations become a visible technical debt backlog. This is useful signal for prioritization conversations you're probably already having.
The [DECISION] pattern is most valuable in existing codebases. A new agent working in an existing codebase has less context than one that was present for the original implementation. The places where specifications are implicit - where conventions were established informally and are "just how we do it here" - are exactly where agents will make decisions that drift. Making the decision-surfacing mechanism explicit and low-friction means those gaps show up as issues rather than as subtle bugs in production. In practice, the first month of using this pattern on an existing codebase will also surface implicit conventions that your human engineers have been navigating by intuition. That's valuable independent of the AI workflow.
The Leader's Version of This Question
Engineering leaders often ask a version of this question: How do I give AI agents more autonomy without losing predictability? The answer is not a better model. The answer is better infrastructure.
The question I'd ask of any team scaling AI development: What is your enforcement layer? Not your instructions. Instructions are advisory. What happens mechanically when an agent doesn't follow them? What runs the tests before the task is complete? What runs lint before the PR is opened? What prevents a bot from merging its own PR? If the answers are "the agent is supposed to remember" and "we review the code manually," you don't have an enforcement layer - you have hope.
When this infrastructure is in place, something shifts in how you lead. Your conversations with staff engineers stop being about implementation status and start being about architectural decisions: what did agents surface this week, what does the pattern of decisions tell us about the spec, where is the briefing document falling short? Sprint planning shifts from estimating implementation time to ensuring that specs are decision-ready before work starts - because a spec with unresolved ambiguities doesn't slow agents down, it silently misdirects them. The leader's job moves upstream, closer to the problem definition and further from the output verification.
That shift is the real productivity gain - not the lines of code per day, but the leverage point. A leader who is spending time reviewing AI-generated code after the fact is doing the wrong job. A leader whose infrastructure surfaces decisions before implementation, encodes outcomes after retros, and enforces contracts mechanically in between has built something that scales.
The red-green-retro cycle is not a new idea. Kent Beck described it in the 1990s. What's new is that the stakes are higher. With one engineer on the keyboard, an implementation that drifts from its tests is a problem. With ten AI agents running in parallel, it's a systemic failure mode.
TDD was always good engineering practice. With AI, it's the load-bearing wall.
Try It Yourself
The issue templates, hooks, and skills from this workflow are in my AI Engineering Playbook - specifically the 03-delivery-cycle/ chapter.
The lowest-friction starting point: copy the [TEST] and [IMPL] issue templates into your project's .github/ISSUE_TEMPLATE/ directory. They encode the protocol as structured forms - the agent gets the right context by default, and the "Done When" checklist makes the test phase explicit rather than assumed.
If you're running Claude Code, the review-tdd-red and review-tdd-green skills give you the second-set-of-eyes review at each phase. The retro skill surfaces what should be encoded after each ticket so the next session starts with that context rather than losing it.
If you want to see TDD baked directly into an AI coding workflow, Superpowers - a Claude Code plugin by Jesse Vincent - enforces red-green-refactor as a first-class constraint, among other structured practices. It's in Anthropic's official plugin marketplace.
The ai-radar project is also open-source - the full CLAUDE.md, hooks, and issue history are there if you want to see what a complete implementation looks like rather than starting from scratch.